This tutorial guides users to set up a stack of Presto, Alluxio and Hive Metastore on your local server, and it demonstrates how to use Alluxio as the caching layer for Presto queries. In this stack, Presto is the SQL Engine to plan and execute queries, Alluxio is the data orchestration layer to cache hot tables for Presto, and Hive Metastore is the catalog service for Presto to read Table schema and location information.
Step1: Download and Launch Alluxio
Go to Alluxio download page, select the latest version (e.g., 2.2.2), download and unpack the tarball.
$ tar -xzf alluxio-2.2.2-bin.tar.gz $ cd alluxio-2.2.2
Start a new deployment with a local Alluxio master and local worker using all default setting:
$ bin/alluxio-start.sh local -f
Mount an S3 bucket which has example input data for this tutorial to the Alluxio file system. Note that this S3 bucket is a public bucket accessible to all AWS users.
$ bin/alluxio fs mount --readonly /example \ s3://apc999/presto-tutorial/example-reason/
So far, we have mounted an S3 bucket with prepared data into Alluxio so we can expose it to Hive Metastore as well as Presto as "local" data.
Step2: Start Hive Metastore
Hive Metastore is commonly used with Presto to serve catalog information such as table schema and partition location. If it is the first time for you to launch Hive Metastore, initialize a new Metastore
$ ${HIVE_HOME}/bin/schematool -dbType derby -initSchema
Edit ${HIVE_HOME}/conf/hive-env.sh to include Alluxio client jar on the Hive classpath, so Hive Metastore can access files stored on Alluxio.
export HIVE_AUX_JARS_PATH=/path/to/alluxio/client/alluxio-2.2.2-client.jar
Start a Hive Metastore which will run in the background and listen on port 9083 (by default).
$ ${HIVE_HOME}/hcatalog/sbin/hcat_server.sh start
One can check the Hive Metastore logs at ${HIVE_HOME}/hcatalog/var/log/
Step3: Download and Launch Presto Server
Goto Presto server installation, download the pre-build server tarball and untar it:
$ tar -zxf presto-server-0.237.tar.gz
Go to directory plugin/hive-hadoop2 to check if there is an Alluxio client jar with a version matching your Alluxio installation. If this is not the case, put the Alluxio client jar under /path/to/alluxio/client/alluxio-2.2.2-client.jar to this directory and remove the outdated Alluxio client if existing.
Edit etc/config.properties file to include
coordinator=true node-scheduler.include-coordinator=true http-server.http.port=8080 discovery-server.enabled=true discovery.uri=http://localhost:8080
Also, edit etc/catalog/hive.properties to point to the Hive Metastore service we just started.
connector.name=hive-hadoop2 hive.metastore.uri=thrift://localhost:9083
Run the Presto server:
$ ./bin/launcher run
Step4: Launch a Presto CLI and Run Queries
Start a Prest CLI connecting to the server started in the previous step.
$ ./presto --server localhost:8080 --catalog hive --debug presto> use default; USE
Create a new table based on the file mounted in Alluxio:
presto:default> DROP TABLE IF EXISTS reason; DROP TABLE presto:default> CREATE TABLE reason ( r_reason_sk integer, r_reason_id varchar, r_reason_desc varchar ) WITH ( external_location = 'alluxio://localhost:19998/example', format = 'PARQUET' ); CREATE TABLE
Scan the newly created table:
presto:default> SELECT * FROM reason; r_reason_sk , r_reason_id , r_reason_desc -------------+------------------+--------------------------------------------- 1 , AAAAAAAABAAAAAAA , Package was damaged 4 , AAAAAAAAEAAAAAAA , Not the product that was ordred 5 , AAAAAAAAFAAAAAAA , Parts missing 6 , AAAAAAAAGAAAAAAA , Does not work with a product that I have 7 , AAAAAAAAHAAAAAAA , Gift exchange 16 , AAAAAAAAABAAAAAA , Did not fit 17 , AAAAAAAABBAAAAAA , Wrong size 18 , AAAAAAAACBAAAAAA , Lost my job 19 , AAAAAAAADBAAAAAA , unauthoized purchase 20 , AAAAAAAAEBAAAAAA , duplicate purchase 21 , AAAAAAAAFBAAAAAA , its is a boy 22 , AAAAAAAAGBAAAAAA , it is a girl 23 , AAAAAAAAHBAAAAAA , reason 23 24 , AAAAAAAAIBAAAAAA , reason 24 25 , AAAAAAAAJBAAAAAA , reason 25 26 , AAAAAAAAKBAAAAAA , reason 26 27 , AAAAAAAALBAAAAAA , reason 27 28 , AAAAAAAAMBAAAAAA , reason 28 29 , AAAAAAAANBAAAAAA , reason 29 30 , AAAAAAAAOBAAAAAA , reason 31 31 , AAAAAAAAPBAAAAAA , reason 31 32 , AAAAAAAAACAAAAAA , reason 32 33 , AAAAAAAABCAAAAAA , reason 33 34 , AAAAAAAACCAAAAAA , reason 34 35 , AAAAAAAADCAAAAAA , reason 35 2 , AAAAAAAACAAAAAAA , Stopped working 3 , AAAAAAAADAAAAAAA , Did not get it on time 8 , AAAAAAAAIAAAAAAA , Did not like the color 9 , AAAAAAAAJAAAAAAA , Did not like the model 10 , AAAAAAAAKAAAAAAA , Did not like the make 11 , AAAAAAAALAAAAAAA , Did not like the warranty 12 , AAAAAAAAMAAAAAAA , No service location in my area 13 , AAAAAAAANAAAAAAA , Found a better price in a store 14 , AAAAAAAAOAAAAAAA , Found a better extended warranty in a store 15 , AAAAAAAAPAAAAAAA , Not working any more (35 rows) Query 20191012_010912_00006_9jx7r, FINISHED, 1 node http://localhost:8080/ui/query.html?20191012_010912_00006_9jx7r Splits: 17 total, 17 done (100.00%) CPU Time: 0.4s total, 83 rows/s, 2.35KB/s, 62% active Per Node: 0.4 parallelism, 37 rows/s, 1.04KB/s Parallelism: 0.4 Peak Memory: 0B 0:01 [35 rows, 1002B] [37 rows/s, 1.04KB/s]
Summary
In this tutorial, we demonstrated how to run setup Presto, Hive Metastore and Alluxio to run SQL queries. Feel free to ask questions at our Alluxio community slack channel.
.png)
Blog

Oracle Cloud Infrastructure has published a technical solution blog demonstrating how Alluxio on Oracle Cloud Infrastructure (OCI) delivers exceptional performance for AI and machine learning workloads, achieving sub-millisecond average latency, near-linear scalability, and over 90% GPU utilization across 350 accelerators.
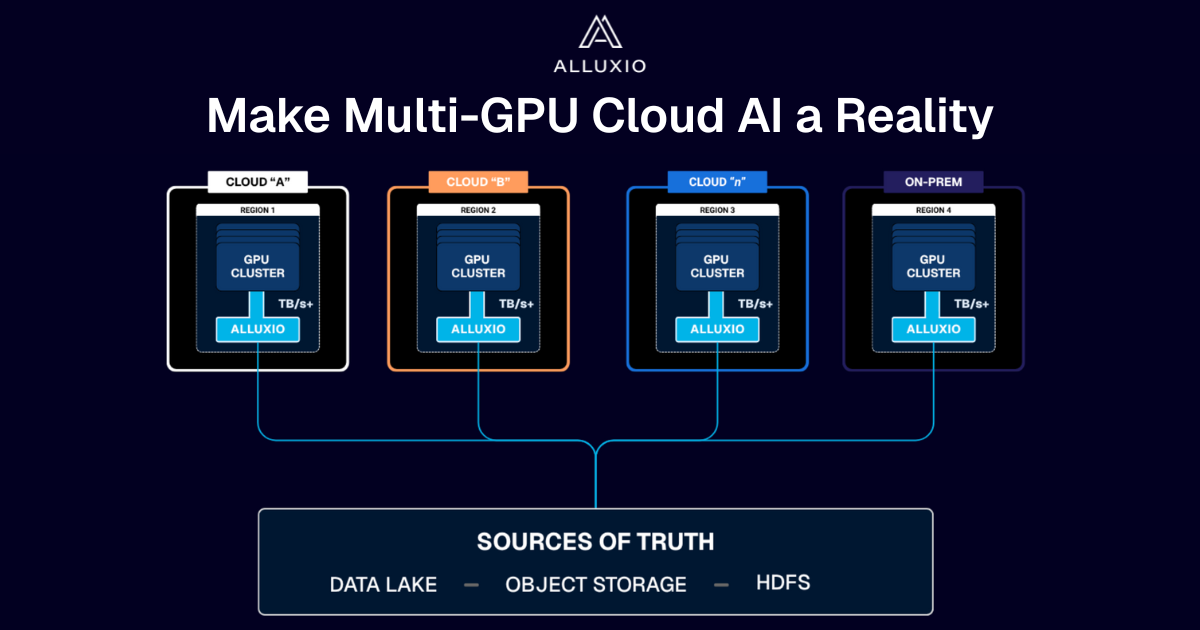
If you’re building large-scale AI, you’re already multi-cloud by choice (to avoid lock-in) or by necessity (to access scarce GPU capacity). Teams frequently chase capacity bursts, “we need 1,000 GPUs for eight weeks,” across whichever regions or providers can deliver. What slows you down isn’t GPUs, it’s data. Simply accessing the data needed to train, deploy, and serve AI models at the speed and scale required – wherever AI workloads and GPUs are deployed – is in fact not simple at all. In this article, learn how Alluxio brings Simplicity, Speed, and Scale to Multi-GPU Cloud deployments.
