A Fortune 50 technology company that serves over 1 billion users successfully implemented Alluxio to achieve a hybrid cloud strategy, become multi-cloud ready, cut costs, and boost agility.
Data acceleration for AI/ML with Alluxio
Deliver up to 4x training performance and up to 2x model distribution speed
Accelerated by Alluxio




Why Alluxio for AI/ML Data Acceleration
Alluxio Enterprise AI provides high-performance data access that intelligently manages data locality and caching across distributed environments.
Accelerate Model Training & Distribution
Deliver up to 4x training performance and up to 2x model serving speed compared to commodity storage
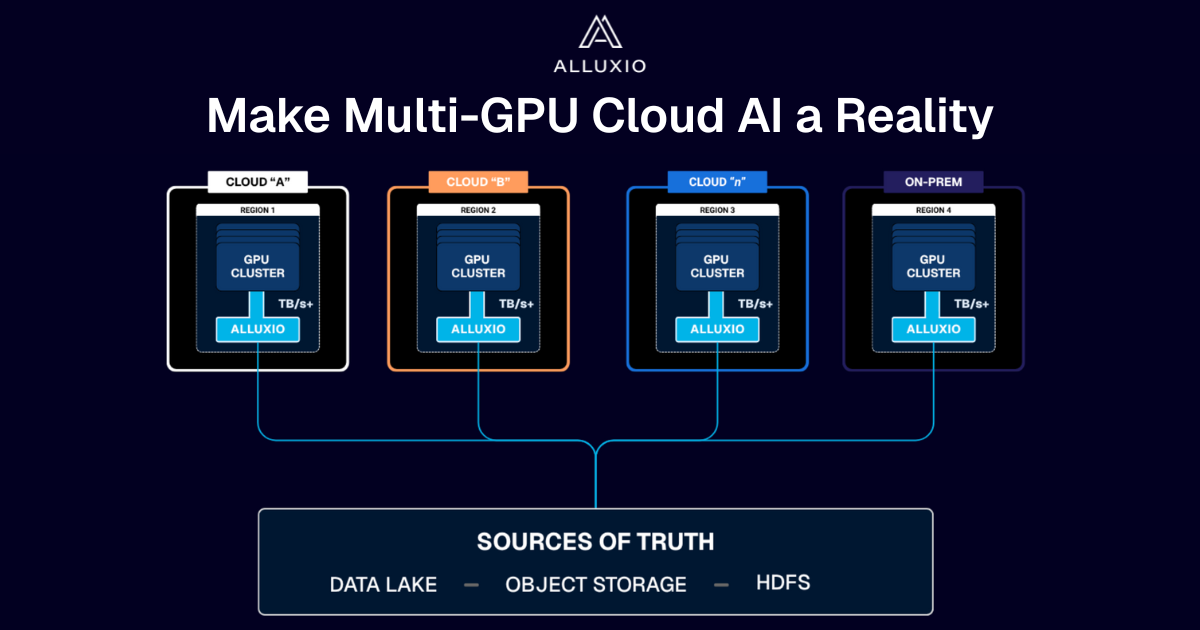
Run on Multi & Hybrid-Cloud Seamlessly
Access data from anywhere, with the same performance as local. Enable AI/ML workloads to run wherever most cost-effective environment
Maximize GPU Utilization
Boost GPU utilization to 97%+ by eliminating data stalls. Keep your GPUs continuously fed with data
Optimize Cloud Spend
Provide a software-only solution that utilizes your existing data lake storage without investing in expensive HPC storage
How it works
Alluxio Enterprise AI provides an intelligent caching system that virtualizes across storage in any environment. Alluxio is an on-prem software that can be seamlessly installed in your existing AI and data infrastructure with zero code changes to applications. Sitting in the middle of compute and storage, Alluxio abstracts across storage resources, bringing data closer to compute.

Supercharge Popular AI Engines like PyTorch, Ray & TensorFlow
Alluxio works with popular AI frameworks like PyTorch, Ray, Apache Spark, and TensorFlow. Alluxio provides the AI engines with fast access to large amounts of data, whether structured or unstructured, on-prem, in public clouds or with hybrid deployments across regions.
Learn more about Alluxio for AIRapid Model Distribution for Serving Across Regions & Clouds
Alluxio accelerates the process of loading the latest models into GPU-enabled instances. By optimizing data transfer across regions and clouds, Alluxio ensures that your serving infrastructure can quickly access and deploy updated models, reducing latency and improving overall system responsiveness.
Accelerate Read/Write on Datasets, Checkpoints & Models in Training
During model training, Alluxio efficiently manages your data reads/writes, including datasets, checkpoints, and model weights. Alluxio delivers up to 7.7GB/sec throughput in Natural Language Processing (BERT) and Biomedical Image Segmentation (3D U-Net) tests. It significantly reduces I/O wait times, allowing your GPUs to operate at peak efficiency.
Check out the MLPerf benchmark report


.jpeg)