Unify Data Lakes Across Multiple Geographic Regions in the Cloud
GPUs are fast, but can your data keep up?




In the world of AI and machine learning, GPUs are powerhouses – but they're only as fast as the data they can access. Alluxio's Enterprise AI platform bridges the gap between your lightning-fast GPUs and your data, wherever it resides.
Get 2-4x faster model training and model distribution compared to commodity storage.
Boost GPU utilization up to 97% by eliminating data stalls and keeping GPUs continuously fed with data.
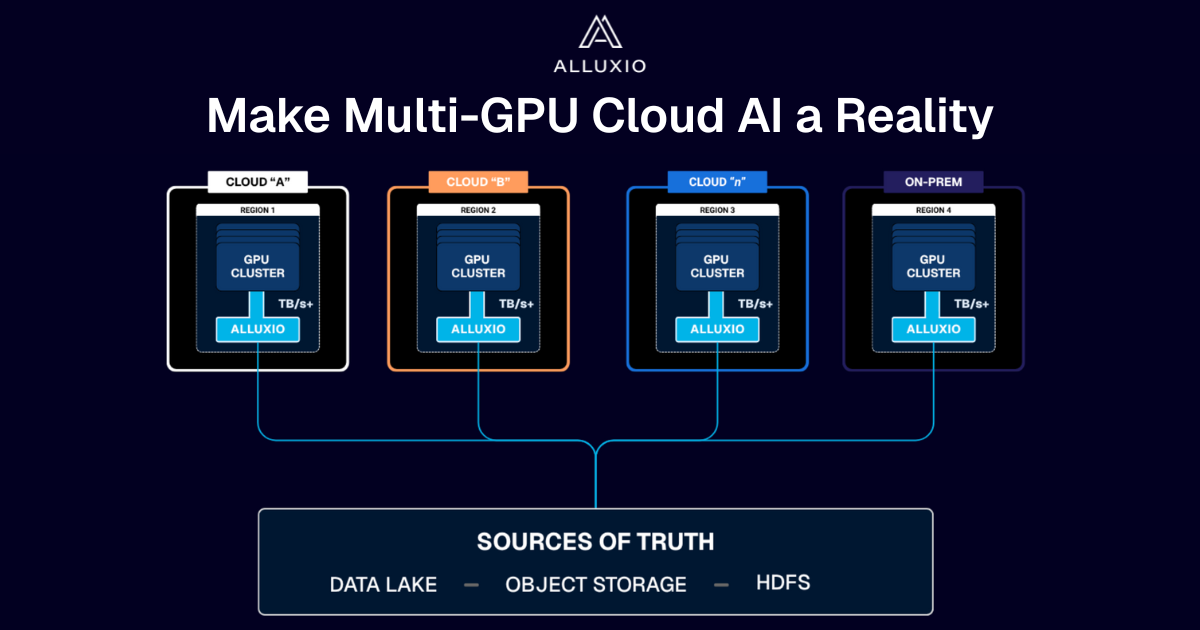
Run AI workloads wherever GPUs can be found – in the cloud, a new region or AZ, or on-premises - without replicating all your data.
Eliminate costly, complex high-performance storage systems and data replication while also lowering cloud storage API and egress costs.
According to a report from Wandb, nearly one third of GPUs have utilization rates less than 15%!

AI workloads demand data input rates of gigabytes to terabytes per second per server to execute at full capacity. While GPUs can handle this demand, storage systems cannot. This mismatch leads to underutilization of your expensive GPU resources.
Alluxio accelerates AI workloads and maximizes GPU utilization by delivering lightning-speed access to petabytes of data spread across billions of files regardless of the underlying storage type or proximity to GPU compute clusters.
Alluxio Distributed Cache deploys between compute and storage in your existing infrastructure. AI workloads gain accelerated performance by accessing data in the Alluxio cache to eliminate storage bottlenecks and maximize GPU utilization.
With Alluxio, GPU utilization typically increases from 30-50% to up to 97%.

Alluxio Distributed Cache brings data closer to AI workloads, maximizing GPU resources and minimizing latency and network traffic. Alluxio ensures consistent, high-speed data access regardless of underlying storage systems or proximity to AI workloads.



.jpeg)