We’re excited to introduce Rapid Alluxio Deployer (RAD) on AWS, which allows you to experience the performance benefits of Alluxio in less than 30 minutes. RAD is designed with a split-plane architecture, which ensures that your data remains secure within your AWS environment, giving you peace of mind while leveraging Alluxio’s capabilities.
Keep reading on for the RAD tutorial on how to deploy Alluxio Enterprise AI in your own AWS cluster and run FIO benchmarks with a few clicks.
Experience the Speed and Ease of Alluxio Enterprise AI on AWS
Alluxio serves as a transformative layer in modern data lake architectures, offering distributed caching capabilities across diverse storage systems. Positioned strategically between training frameworks like PyTorch and TensorFlow and cloud object stores such as Amazon S3, Alluxio accelerates data access by caching frequently accessed data. This leads to reduced latency, faster training iterations, and significant cost savings by minimizing direct data retrievals from cloud storage. Moreover, Alluxio’s unified namespace simplifies data management, enabling data scientists to seamlessly interact with data across various storage backends without extensive data migration.

Rapid Alluxio Deployer on AWS Highlights

1. Effortless Deployment and Management: RAD on AWS is designed for seamless integration with minimal setup. It works out of the box, allowing your team to concentrate on developing business logic rather than managing infrastructure.
2. Enhanced Security: Our split-plane architecture ensures that your data remains secure within your environment, giving you peace of mind while leveraging Alluxio’s capabilities.
3. Accelerated Data Access: Experience the benefits of rapid, seamless data access in under 30 minutes, optimizing your workflow and productivity.
4. User-Friendly Interface: Our intuitive WebUI simplifies the admin workflow, streamlining administrative tasks and eliminating the need for complex manual deployment and configurations.
5. Optimized for AWS and S3: Our initial release focuses on AWS and S3, two of the most widely used platforms, ensuring broad compatibility and immediate value.
Storage I/O Performance Benchmark
As AI and ML become increasingly prominent, driving new ways of living and working, more and more companies are jumping on the bandwagon. For ML engineers, however, storage hardware is often the last thing on their mind. Despite this, storage performance is a critical consideration, because large AI systems, especially those used for fine-tuning extensive models, frequently depend on remote shared storage. This is essential not only because massive datasets cannot be housed on a single server but also because shared storage facilitates efficient GPU and data sharing across the cluster. Ensuring that storage is fast enough to keep multiple GPUs busy with data is vital for maintaining optimal performance.
There have been many efforts to benchmark this I/O performance. Over the past few years, FIO has become the tool of choice for testing storage I/O performance in Linux (reference blog from Nvidia). It can simulate various types of read operations, whether sequential or random, and allows for different configurations like parallel threads and data size.
In this context, we'll use RAD to deploy Alluxio AI and run Fio microbenchmarks to illustrate the performance advantages of using Alluxio. Continue reading for more information.
Note: The pre-req is an AWS account, and the demo will cost you about $15.
Tutorial
In this tutorial, we'll guide you through the complete process of signing up and logging into RAD, launching an Alluxio AI cluster, and executing the FIO benchmark. To showcase the advantages of Alluxio AI, we'll compare data read performance (focusing on the latency here) with and without Alluxio caching.
- Cold Read (data not in Alluxio cache): First, we'll perform an initial read to measure the time it takes to retrieve data from a remote source. This will be our baseline for comparison.
- Hot Read (data in Alluxio cache): During the initial cold read, Alluxio AI will cache the data. The next time we read the same dataset, it will be a "hot read" from the cache, which should be significantly faster.
We will run sequential read first then repeat for random read. This full demo will take approximately 40 min, mostly due to waiting times. Feel free to enjoy a coffee break during the longer phases.
Part I: Sign up for RAD and Account Creation (5 min)
Visit https://signup.alluxio-rad.io/ to get started. After completing the form, expect to receive an email with a confirmation link. Click on the link to verify your account. Optionally set a custom subdomain name, which will be the prefix of the UI URL in the form of <subdomain>.alluxio-rad.io
In about 10 minutes after confirming, a second email will be sent containing the login information to your unique URL to login to the UI.
Part II: Create Managed Access on AWS (5 min)
A Managed Access contains the necessary information to allow the service to access your AWS account to perform the necessary operations to deploy the Alluxio cluster. Because all resources are created within the user's AWS account, this sequence of steps must be completed before defining the Alluxio cluster. Learn more about the split plane architecture to understand the purpose of this step.
https://youtu.be/2r7L2jbNsEo
Part III: Create Alluxio cluster (2 min + 30 min Wait)
In this part we will deploy the Alluxio AI cluster in your AWS environment with a few clicks. It will take you about 1 minute to set the demo Alluxio cluster up on the UI, and about 30 min wait to launch it in the background.
https://www.youtube.com/watch?v=nIT4P8V_H_o
Part IV: Run Benchmarks (10 min)
Now we are ready to run the FIO microbenchmark mentioned in the previous section.
Note:
- We will do cold/ hot read comparison for sequential read first then repeat the steps for random read.
- In order to run cold read again with the same dataset for random read, we would need to do cache eviction in between.
https://www.youtube.com/watch?v=StErjysOCeE
Part V: Delete cluster (1 min + 5 min wait)
Once you are done, please remember to delete the Alluxio cluster through RAD. This is an easy but important step at end of the demo so that we don’t continue to incur costs in your AWS account.
https://www.youtube.com/watch?v=7bSEMQ4q2QM&t=1s
Congratulations! You have successfully finished the demo of launching Alluxio cluster and run a FIO microbenchmark!
Learn More
Join the upcoming webinar on Sep 10, 2024 11:00 AM PT to learn more about how you can leverage Alluxio as a data caching layer as an alternative approach to the expensive HPC storage. Register now: https://us06web.zoom.us/webinar/register/WN_5527zTekQQa355E_oRyLTA.
.png)
Blog

Oracle Cloud Infrastructure has published a technical solution blog demonstrating how Alluxio on Oracle Cloud Infrastructure (OCI) delivers exceptional performance for AI and machine learning workloads, achieving sub-millisecond average latency, near-linear scalability, and over 90% GPU utilization across 350 accelerators.
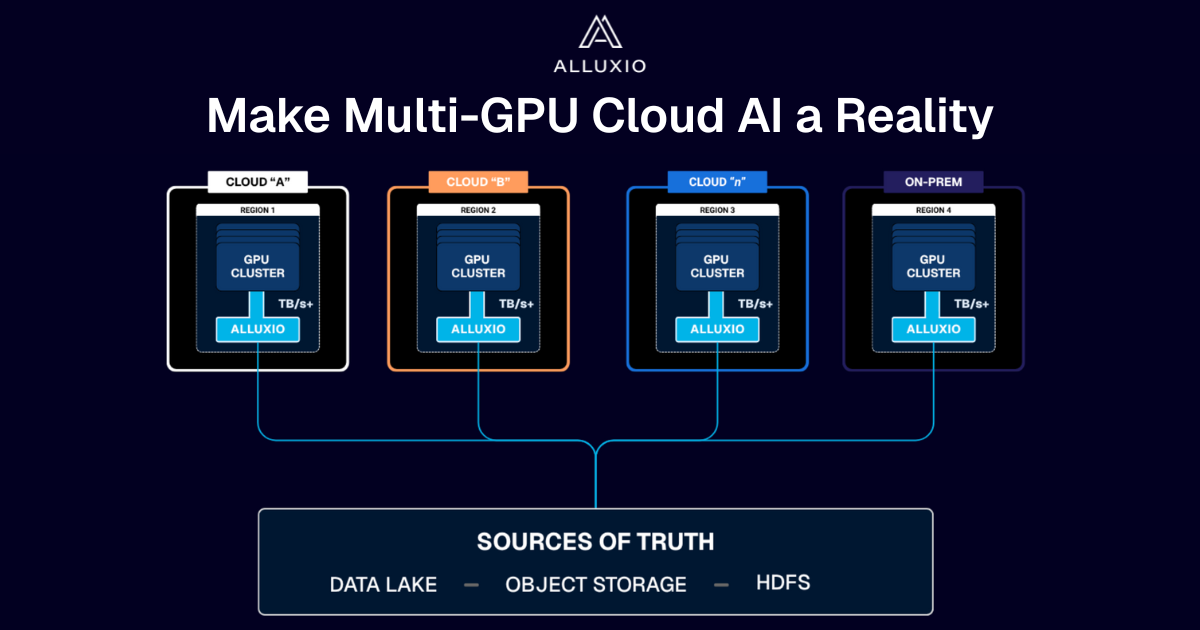
If you’re building large-scale AI, you’re already multi-cloud by choice (to avoid lock-in) or by necessity (to access scarce GPU capacity). Teams frequently chase capacity bursts, “we need 1,000 GPUs for eight weeks,” across whichever regions or providers can deliver. What slows you down isn’t GPUs, it’s data. Simply accessing the data needed to train, deploy, and serve AI models at the speed and scale required – wherever AI workloads and GPUs are deployed – is in fact not simple at all. In this article, learn how Alluxio brings Simplicity, Speed, and Scale to Multi-GPU Cloud deployments.
