We just announced our amazing Q2 results with customer growth, sub-millisecond latency capability and record MLPerf Storage 2.0 results. Here is a quick summary of the announcement.
This quarter marked a phenomenal period for Alluxio as we launched Enterprise AI 3.7, our most advanced release yet, delivering sub-millisecond TTFB latency for AI workloads accessing cloud storage. The new 3.7 version of Alluxio AI achieves up to 45× lower latency than S3 Standard and 5× lower latency than S3 Express One Zone, while delivering impressive throughput of up to 11.5 GiB/s per worker node with linear scalability. Read more about what’s new with Alluxio AI 3.7 here: https://www.alluxio.io/blog/alluxio-ai-3-7-now-with-sub-millisecond-latency.
Our customer momentum has been exceptional, with over 50% growth in the first half of 2025 compared to the previous period. We've welcomed notable new customers, including Salesforce, Dyna Robotics, and Geely, spanning industries from tech and finance to e-commerce and media. These organizations are leveraging Alluxio's AI acceleration platform to enhance training throughput, streamline feature store access, and speed up inference workflows across hybrid and multi-cloud environments. Learn more about the collaboration of Alluxio with Salesforce in this white paper: https://www.alluxio.io/whitepapers/meet-in-the-middle-for-a-1-000x-performance-boost-querying-parquet-files-on-petabyte-scale-data-lakes.

Alluxio's leadership in AI infrastructure was further validated in the quarter by our outstanding MLPerf Storage v2.0 benchmark results. Our distributed caching architecture achieved exceptional GPU utilization rates, with 99.57% for ResNet50 and 99.02% for 3D-Unet, while delivering substantial throughput gains across diverse training and checkpointing workloads. These results underscore our core mission: keeping GPUs fed with data at the speed they require for maximum ROI on infrastructure investments.
As we head into the second half of our 2026 fiscal year, we're more energized than ever about the future of AI infrastructure. With enterprise demand for high-performance AI workloads accelerating rapidly and our technology proving its value at scale, we're positioned to help organizations unlock unprecedented speed and efficiency in their AI initiatives. The best is yet to come!
.png)
Blog
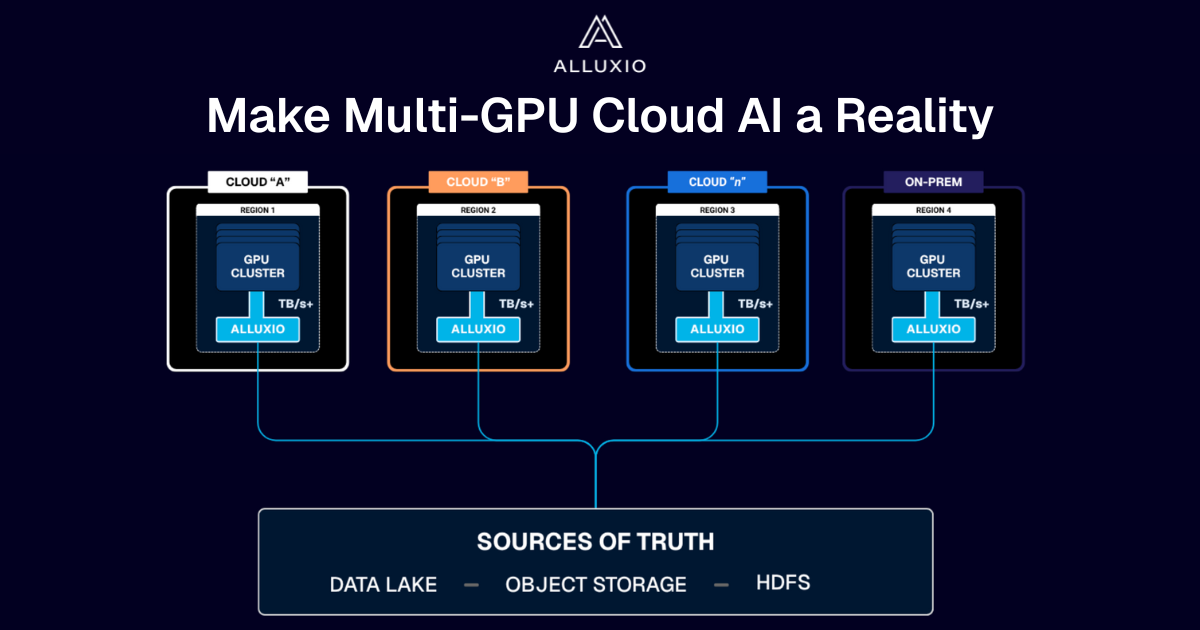
If you’re building large-scale AI, you’re already multi-cloud by choice (to avoid lock-in) or by necessity (to access scarce GPU capacity). Teams frequently chase capacity bursts, “we need 1,000 GPUs for eight weeks,” across whichever regions or providers can deliver. What slows you down isn’t GPUs, it’s data. Simply accessing the data needed to train, deploy, and serve AI models at the speed and scale required – wherever AI workloads and GPUs are deployed – is in fact not simple at all. In this article, learn how Alluxio brings Simplicity, Speed, and Scale to Multi-GPU Cloud deployments.

