Cloud object storage like S3 is the backbone of modern data platforms — cost-efficient, durable, and massively scalable. But many AI workloads demand more: sub-millisecond response times, append and update support, and the ability to seamlessly support AI workloads as they scale across clouds and on-premises datacenters.
Alluxio turbo-charges your existing object storage, giving you the speed and efficiency required for next-generation AI workloads — without giving up the scale, durability, and economics of S3.

Why S3 Alone Isn’t Enough for AI
Amazon S3 is unbeatable for scale, durability, and cost. But when workloads shift from batch analytics to AI training, inference, feature stores, and agentic memory, cracks appear:
- Latency: Standard S3 read latency is often 30–200 ms — acceptable for ETL, but crippling for model training, inference, and agentic memory, retrieval-augmented generation (RAG), and feature store lookups.
- Limited semantics: Appends and renames aren’t natively supported by standard S3 buckets, preventing workflows that depend on write-ahead logs or iterative updates.
- Metadata bottlenecks: Listing millions of objects can be slow and expensive, dragging down iterative ML pipelines.
S3 is brilliant as a capacity store. But for AI workloads that need real-time performance, it falls short. The question most architects ask:
“Can I meet AI latency and semantics requirements without replacing S3 and without introducing complex data migration or cloning workflows?”
Make S3 Ready for AI with Alluxio
Alluxio sits transparently between your AI applications and S3 (or any object store), transforming S3 into a low-latency and high-throughput data store with enhanced semantics that’s ready for AI:
- Sub-ms Latency: Cache frequently accessed training data, model files, embeddings, or Parquet files on NVMe for sub-millisecond time-to-first-byte (TTFB).
- TiB/s throughput: Push terabytes per second of throughput with a single Alluxio cluster that scales horizontally with additional Alluxio Worker nodes.
- Semantic Enhancement: Enable append, write backs, and cache-only updates — features that object stores lack natively.
- Kubernetes Native: Run side-by-side with your GPU clusters, scale linearly with your workloads, and monitor with built-in observability.
- Zero Migration: Mount existing S3 buckets as-is; no rewrites, no data moves. Unlike single-node API-translation tools such as s3fs, Alluxio is fully distributed and cloud-native, implementing decentralized metadata and data management.
What about Amazon FSx for Lustre and S3 Express One Zone? Both deliver improved latency compared to S3 Standard but can be cost prohibitive and have other drawbacks. Think of it this way:
- FSx for Lustre is a high-speed POSIX filesystem but requires provisioning and has no S3 API interface.
- S3 Express One Zone offers low-latency object access — but only within a single AZ and requires manual data migration from S3 Standard — plus, it costs roughly 5X more than S3 Standard.
Alluxio is the best of all worlds, delivering low-latency performance with the flexibility to access data via POSIX or S3 APIs – all without changing your storage backend or migrating data and at a fraction of the cost of FSx and S3 Express.
| Feature |
S3 Standard
|
S3 Express
|
FSx Lustre
|
Alluxio + S3
|
|---|---|---|---|---|
|
Latency (TTFB)
|
100+ ms
|
1–10 ms
|
1 ms
|
< 1 ms
|
|
Multi-cloud
|
🔴
|
🔴 | 🔴 | 🟢 |
|
POSIX API
|
🔴 | 🔴 |
🟢
|
🟢 |
|
S3 API
|
🟢
|
🟢 | 🔴 | 🟢 |
|
Support Append
|
🔴
|
🟢 | 🟢 | 🟢 |
|
Data Migration Required
|
No |
Yes
|
No | No |
|
Cost ($/TB/mo)
Assuming 20% hot data
|
~$231 | ~$1102 | ~$1433 | ~$234 to ~$425 |
1 Assumes S3 standard ($0.023 per GB-month) is the source of truth, hoping full data
2 Assumes S3 Express One Zone ($0.110 per GB-month) holding full data, as it needs to be decided at bucket creation time
3 Assumes for 1,000 MB/s/TiB class, FSx Lustre ($0.600 per GB-month) holding 20% hot data, while S3 standard ($0.023 per GB-month) keeps full data
4 Assumes Alluxio deployed on GPU spare disks holding 20% hot data, no additional hardware cost, while S3 standard ($0.023 per GB-month) keeps full data
5 Assumes a separate Alluxio cluster holding 20% hot data using i3en.6xlarge instances ($2.023 per hr, 1 yr reserved, with 15TB NVMe attached), while S3 standard ($0.023 per GB-month) keeps full data - i3en.6xlarge instances ($2.023 per hr / 15TB ) * 20% + S3 Standard ($23) = $42.4 per TB-month
Proven In Customers Environments
Alluxio’s impact is real and measurable for AI workloads:
Agentic Memory on Datalakes for LLMs
Salesforce [ READ CASE STUDY ]
- Challenge: Lookups into Parquet files on S3 breach P99 SLAs (1ms)
- Solution: Alluxio distributed SSD caching of S3 data
- Result: 1000x faster TTFB; Lookup latency <1 ms.
Low-Latency Feature Store
Blackout Power Trading [ READ CASE STUDY ]
- Challenge: Training 100K+ models on 10M Parquet files in S3 was bottlenecked by 30–100 ms latency.
- Solution: Alluxio cached Parquet data on SSDs.
- Result: Training time reduced with 32X faster feature store queries, inference time reduced with 83X faster feature store queries; GPU utilization >90%.
Model Training & Fine-Tuning
RedNote [ READ CASE STUDY ]
- Challenge: Unable to train petabyte+ model within 6-hour SLA
- Solution: Alluxio distributed SSD caching of AI training data
- Result: Training time reduced up to 50% and GPU utilization 45%
Alluxio Key Metrics & Benchmarks
Alluxio is a horizontally scalable distributed cache that scales linearly with additional Alluxio Worker nodes. At scale, Alluxio delivers
- Latency: Cache hits return in less than 1 millisecond
- Throughput: Terabytes per second with a single Alluxio cluster
- GPU utilization: >90% sustained in MLPerf training benchmark
- Scale-out: Scales linearly; no single point bottlenecks
The following ‘micro benchmarks’ showcase a single Alluxio Worker responding to requests from a single client with increasing levels of concurrency or threads:
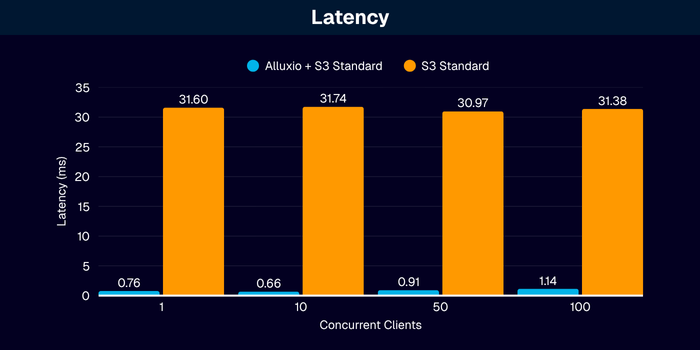
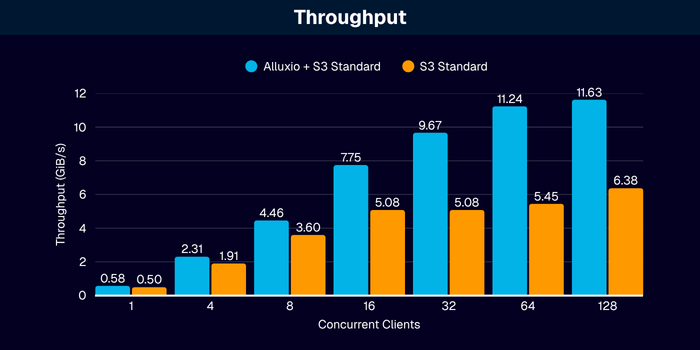
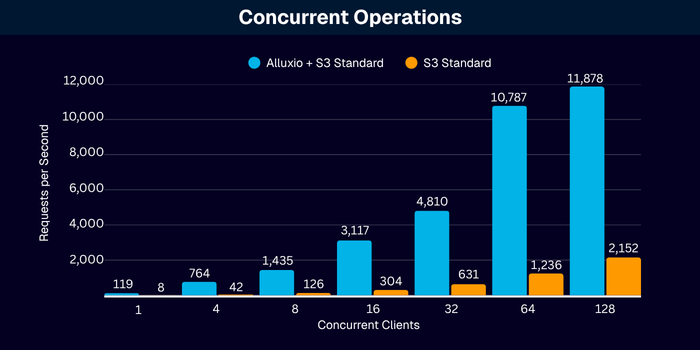
Conclusion
S3 gives you capacity, durability, and economics at scale. By layering in Alluxio, you make S3 AI-ready with sub-ms latency, linear scalability, and seamless support for advanced AI workloads — all without giving up your existing S3 investment.
If you’re building AI platforms, the choice is clear:
Keep S3 as your source of truth.
Layer in Alluxio for AI at max throughput and ultra low latency.
Ready to accelerate your cloud storage? Schedule time with an Alluxio expert.
.png)
Blog

Learn about the new features in Alluxio AI 3.8 designed to eliminate two of the most painful bottlenecks in modern AI pipelines. Introducing Alluxio S3 Write Cache, which dramatically reduces object store write latency and improves write-heavy workload performance, and Safetensors Model Loading Acceleration that delivers near-local NVMe throughput for model weight loading

For write-heavy AI and analytics workloads, cloud object storage can become the primary bottleneck. This post introduces how Alluxio S3 Write Cache decouples performance from backend limits, reducing write latency up to 8X - down to ~4–6 ms for concurrent and bursty PUT workloads.

Oracle Cloud Infrastructure has published a technical solution blog demonstrating how Alluxio on Oracle Cloud Infrastructure (OCI) delivers exceptional performance for AI and machine learning workloads, achieving sub-millisecond average latency, near-linear scalability, and over 90% GPU utilization across 350 accelerators.