This blog shares the practice of using Alluxio and Spark to accelerate the auto data tagging system in WeRide, an autonomous driving technology company.
About WeRide

WeRide is a global leading company that develops L4 autonomous driving technologies. Established in 2017, WeRide is headquartered in Guangzhou, China, and maintains R&D and operation centers in Beijing, Shanghai, Nanjing, Zhengzhou, Shenzhen, as well as San Jose in the USA.
WeRide launched China’s first commercial Robotaxi service, completely open to the public in 2019. Now WeRide offers an all-rounded product mix on the Robottaxi, Mini Robotbus, and Robotvan. We provide multiple services including online ride-hailing, on-demand transport, and urban logistics.
Why Alluxio
There are three major benefits Alluxio provides – it’s fast, simple, and easy to use.
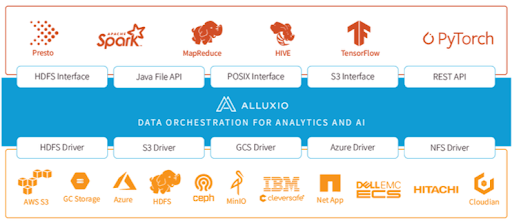
First, Alluxio is fast as it provides distributed caching. Memory speed I/O is provided by Alluxio's caching service. In addition, the tiered storage can leverage both memory and disk, making it elastic to scale data-driven applications in a cost-effective way. Second, Alluxio provides simplified and unified data access and data management. Finally, it's very easy to deploy and use Alluxio in the existing data platform. For example, Spark can run on top of Alluxio without any code changes, just one line of configuration change.
How Are We Using Alluxio at WeRide
Autonomous Driving Development

The diagram above shows a typical workflow of autonomous driving development in WeRide. We start with data collection, collecting sensor data from the test vehicle fleets every day. Once the data is collected, we upload it to the cloud. The data is then processed and analyzed. Afterward, we will do data labeling, HD map labeling, and development. Next, we will perform machine learning model training for AI algorithm development. Simulation and validation will also be conducted. Finally, we will deploy both on-boarding vehicle fleets and off-boarding servers.
We have both hardware and software in the loop. The biggest challenge is the size of the data. We generate many terabytes of data every day and have accumulated millions of kilometers of mileage, so the entire size is in petabytes. This requires vast amounts of storage and significant computing power.
Data Tagging
Tags are sometimes confused with labels. In autonomous driving, tags usually mean scenarios, while labels can be obstacles or boxes.
For example, the left image below shows a lane-change scenario and the right image is a right-turn scenario. We will tag a sequence of frames with lane-change or right-turn tags. The labels here are the lane, the surrounding vehicles, obstacles, and the traffic lights, which are different from tags.

In a data-driven autonomous driving workflow, data tagging plays an essential role in data analytics. With the tagging results, we can do data selection to support the downstream pipelines, including model training, benchmark, and long-tail evaluation.
Alluxio + Spark in Kubernetes
An end-to-end tagging pipeline is to collect and upload the ROS (Robot Operating System) bag files from the test vehicles and then convert them into Parquet format. After that, we can run Spark jobs to perform data analytics algorithms. From there, we can export the tagging results to downstream pipelines.

As can be seen above, the system architecture is quite typical. We build and run applications on hybrid cloud with both public cloud and on-prem datacenters with the following considerations: the on-prem datacenter is more cost-effective and can be customized, while public cloud is easy to scale.
In both public cloud and on-prem data centers, we use Kubernetes to manage the computing resources of the CPU and the GPU clusters and to schedule the workflow and tasks. In the storage layer, we use MinIO to build S3 compatible object storage service.
Alluxio provides a fast, simplified, unified data layer that bridges S3, MinIO and Spark, and other data analytics applications so that the data tagging workflow is accelerated with the introduction of Alluxio.
Test Results

We followed Alluxio documentation for the deployment. We used the helm chart to deploy a test cluster across the CPU and GPU clusters for 42 workloads. We used tiered storage - level zero is the memory with 50G, and level one is the SSD with 200G. Based on 42 worker nodes, we ended up with 2TB of memory and 8TB of SSD.
For the data tagging tests, there's only one line of a configuration change, which is very easy to use. We have added Alluxio into the command-line tools, but Alluxio is enabled by default and hidden from the end-users.
Overall, the test shows approximately 7x faster in performing tagging tasks with the introduction of Alluxio.
Future Work
Use Alluxio as a Unified Data Orchestration Layer
We plan to build the unified data layer with Alluxio as the data orchestration layer. Our goal is to integrate with more applications, including Presto, HIVE, and TensorFlow, which are the services already running inside WeRide.

Furthur Accelerate the Workflow with Spark + GPU + Alluxio
We are integrating Spark, RAPIDS, and GPU with Alluxio to get more acceleration, not just for auto data tagging but also in many other applications.

About the Authors
Feifei Cai, Senior Software Engineer in WeRide Data Team. He is responsible for the data tagging system at WeRide. His experience includes cloud, Kubernetes, and distributed systems.
Hao Zhu, Senior Software Engineer in WeRide Data Team. He is experienced in both cloud and on-premise data centers.
.png)
Blog

Learn about the new features in Alluxio AI 3.8 designed to eliminate two of the most painful bottlenecks in modern AI pipelines. Introducing Alluxio S3 Write Cache, which dramatically reduces object store write latency and improves write-heavy workload performance, and Safetensors Model Loading Acceleration that delivers near-local NVMe throughput for model weight loading

For write-heavy AI and analytics workloads, cloud object storage can become the primary bottleneck. This post introduces how Alluxio S3 Write Cache decouples performance from backend limits, reducing write latency up to 8X - down to ~4–6 ms for concurrent and bursty PUT workloads.

Oracle Cloud Infrastructure has published a technical solution blog demonstrating how Alluxio on Oracle Cloud Infrastructure (OCI) delivers exceptional performance for AI and machine learning workloads, achieving sub-millisecond average latency, near-linear scalability, and over 90% GPU utilization across 350 accelerators.