Alluxio is the data acceleration platform that improves the performance of data-intensive AI and analytics workloads and unifies data silos across heterogeneous environments. This is the last article in a series to give you the basics of Alluxio’s architecture and solution. Please also check out the series here: use case overview, Presto + Alluxio overview, machine learning training with Alluxio overview.
Apache Spark is an open source computation framework that supports a wide range of analytics — ETL, SQL queries, machine learning, and streaming computation. Spark’s in-memory data model and fast processing make it widely adopted by data-driven organizations.
For a global data platform, the following factors often result in slow time-to-value, high costs, and reduced agility:
- Today, data resides in silos, including data lakes, data warehouses, and object stores, whether on-premises, in the cloud, or spanning multiple geographic locations. It is challenging to find a solution that unifies data from many sources and serves it efficiently to Spark.
- An end-to-end data pipeline requires Spark to be used along with other compute frameworks like Presto, TensorFlow, etc., which requires a holistic approach to design the architecture of the data platform. Furthermore, organizations are stuck with legacy data platforms built in the pre-cloud era and lack cloud-native capabilities or require complex migrations to the cloud.
Alluxio empowers Spark by accelerating data processing, reducing cloud storage API costs, unifying data silos, providing data sharing across compute frameworks, and seamlessly migrating data across different environments.
By bringing Alluxio together with Spark, you can modernize your data platform in a scalable, agile, and cost-effective way. In this post, we provide an overview of the Spark + Alluxio stack. We explain the architecture, discuss real-world examples, describe deployment models, and showcase performance and cost benchmarking.
Why Alluxio
Alluxio is a data acceleration platform that sits between computing (such as Spark, Presto, Tensorflow, MapReduce) and storage (such as Amazon S3, HDFS, Ceph) for both architectural and business benefits.
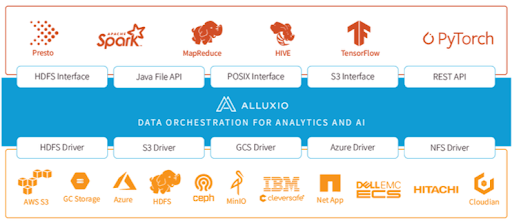
Architectural Benefits
Unified Data Access – Unify Data Silos and Access without Data Movement
Ideally, you want a single source of truth for your data, but silos are inevitable with a growing number of analytics applications and business teams. Replicating data from myriad sources into a central repository is no longer feasible as it involves manually moving and duplicating data across silos, which is both time-consuming and error-prone.
Alluxio unifies all sources of data by creating an abstraction layer between compute and storage. The unified namespace allows access to multiple independent storage systems regardless of physical location. The following architectural advantages are realized:
- A single source of truth for Spark and more: Alluxio provides a single data access point for all data regardless of where it resides. Because Alluxio abstracts the storage layer, you can mount any storage system into Alluxio like a folder. Spark only needs to connect to Alluxio, which handles the complexity of connecting different domains under the hood.
- Eliminate manual copies and unnecessary data movement: Since Alluxio represents a single view of all the data, you no longer need to manage data copies or move data around manually. Data remains where it is stored — on-premises, in the cloud, or both — and data in Alluxio is automatically synchronized with the underlying storage in the case of updates or other changes. Alluxio maintains the latest copy of the data or fetches it from under storage, so data freshness is assured.
- Enable decoupled compute and storage: The architecture of decoupling compute and storage optimizes the allocation and utilization of storage and compute resources. But it also brings latency concerns, especially when data is remote. Alluxio can deploy co-located with Spark and manage its storage media. When Spark accesses remote data, the performance is as if it is local because Alluxio provides hot data locality to the applications.
- No impact to the application side. When making changes to the storage side, existing data analytics applications, including Spark, can run on top of Alluxio without any code changes. By providing the same API for existing applications, Alluxio creates a seamless experience for end-users, accelerating the adoption of new tech stacks.
Efficient Data Sharing – High-Performance Data Sharing Across All Compute Frameworks
The typical data processing pipeline is a series of steps, including data ingestion, data preparation, analytics, and machine learning. You may utilize one compute engine followed by another, such as ETL with Spark followed by a SQL query using Spark or Presto, followed by machine learning training using Spark MLib or PyTorch on the query’s result.
Alluxio spans the entire data pipeline and enables data sharing as a distributed cache for multiple data sources shared across multiple steps. Data ingestion, ETL, analytics, ML can share intermediate results so that one compute engine can consume the output of another. The following architectural benefits are realized:
- Enhanced performance across all compute engines. As Alluxio spans the entire data pipeline, it allows any computation framework to use previously cached data to benefit both read and write workloads. Alluxio manages the local storage on the compute nodes (with Spark and other compute frameworks). When a Spark job in the ingest phase writes to Alluxio, the same data is cached in Alluxio and available for future stages. Beyond accelerating Spark, the entire data pipeline has better end-to-end performance.
- Drive up data throughput for the entire data pipeline. With the advancement of the compute processing power, certain workloads become I/O bound instead of compute-bound. Alluxio enables higher read/write throughput with data locality. In workloads that require a large amount of I/O, such as machine learning training, reducing the network traffic and increasing the data throughput significantly improves the utilization of expensive GPU resources. Thus, data platforms can achieve better resource utilization.
Seamless Data Migration – Modernize Your Data Platform and Accelerate Cloud Migration
Applications built on Spark rely on the underlying data platform, which must keep scaling and modernizing to meet the ever-growing demands of both workloads and data. When your data platform cannot handle the volumes or velocity of data, you begin to consider migration. You may want to get rid of legacy platforms, but data migration is never easy, whether from on-premises to the cloud or just moving data from one data center to another.
This is where Alluxio comes into the picture. Alluxio presents a unified view across various heterogeneous sources. With Alluxio, you can migrate the data pipeline incrementally from the on-premises environment to the cloud with a hybrid data platform. Alluxio can achieve moving data from one storage system to another seamlessly while you are running Spark jobs without interruption.
- Hybrid cloud bursting. Your cloud migration journey may begin with the primary data source on-premises and the use of Spark in a public cloud. “Zero-copy” hybrid cloud bursting allows you to start leveraging computing in the cloud with data left on-premises. Your on-premises data platform can coexist with a cloud-based modernized data platform as you begin the migration journey.
- Live data migration to cloud storage with zero downtime. Traditionally, migration involves first copying data from the source to the destination, updating all existing applications with new URIs, and removing the original data copies. Using Alluxio's data migration policies, this can be done seamlessly. The applications and catalogs of data remain uninterrupted when data is moved from on-premises storage to the cloud, or from one data center to another.
- Enable hybrid and multi-cloud architecture. Hybrid cloud is often an architectural choice instead of an intermediate step. Legacy and modern systems can exist simultaneously, in hybrid or multi-cloud environments, to meet compliance requirements, to protect your existing investments, and to avoid cloud vendor lock-in. Alluxio allows for a low-latency hybrid architecture and the performance as if data is on the cloud compute cluster. Data can be managed in a secure manner regardless of location.
Business Value
Ultimately, Spark is serving business analysts and data scientists who derive value from data for your organizations. By using Alluxio with Spark, you will benefit from data orchestration that empowers your organization to get quicker answers, boost operational efficiency, reduce costs, and be more flexible and agile.
Faster Time-to-Insights
Data platform engineers are often overwhelmed with requests from business users. Organizations are forced to wait a long time for answers to critical questions, resulting in slow time-to-value.
With Alluxio, data is immediately available for quicker data-driven insights because Alluxio provides a single source of truth for siloed data. Also, high performance enabled by Alluxio can significantly reduce wait times and allow organizations to realize value faster and have the capacity to answer more questions than before. Faster time to insight for your organization translates to better-informed decisions, which provides a crucial competitive advantage.
Significant Cost Savings
One of the key motivations of moving to the cloud is the ability to cost-effectively scale up or down to avoid having to purchase new storage hardware. Alluxio helps to take full advantage of cloud benefits.
When you utilize cloud object stores, Alluxio helps reduce a large amount of network egress costs by caching data, which avoids repeatedly fetching data directly from the cloud storage. Furthermore, Spot Instances are a cost-effective choice if you can be flexible about when your Spark applications run and if they can be interrupted. Alluxio can be deployed as a stand-alone cluster for delivering high availability and fault tolerance, which allows scaling cache separately from Spark on spot instances. We provide a cost benchmark using spot instances in part 3.2.
Organizational Agility and Flexibility
Alluxio empowers organizations to democratize their data access by unifying data silos. With less pressure on data platform engineers, it is easy to onboard new use cases, since there is no need to redesign the data pipeline. This greatly reduces the time it takes to provision new infrastructure and decreases the operational costs to maintain the infrastructure.
Alluxio also provides the freedom and convenience to plug new innovative tech stacks into your data platform. The data environment today will not be the same a year or two in the future. It is important to have an architecture that is compute-agnostic, storage-agnostic, and cloud-agnostic to adapt as tech stacks and business needs change, which is where Alluxio comes in. With Alluxio, you will get freedom at all layers in the technology stack.
Common Use Cases and Real-World Case Studies
Here, we present three of the most common Spark use cases with Alluxio, each with a real-world example.
Boost Model Training Efficiency by Data Sharing from Preprocessing to Training
The first use case is data sharing between compute frameworks. We use machine learning workloads as an example. Machine learning workloads often make more frequent I/O requests to a larger number of smaller files than traditional data analytics applications. Alluxio enables data sharing spanning the end-to-end pipeline of data preprocessing, loading, training, and output is all well supported. By enhancing the I/O efficiency, the pipeline speed and GPU utilization can be significantly increased. Alluxio is proven to achieve 9x improved I/O efficiency.

Boss Zhipin (NASDAQ: BZ) is the largest online recruitment platform in China. At Boss Zhipin, Alluxio is used as the data sharing layer for ETL and model training. Spark and Flink read data from Alluxio, preprocess the data, and then write back to Alluxio cache. In the backend, Alluxio persists the preprocessed data back to Ceph and HDFS. TensorFlow, PyTorch, and other Python applications can then read preprocessed data from Alluxio for training without waiting for writing to Ceph or HDFS to complete. To learn more, watch the talk (in Chinese) here.
Hybrid Cloud Analytics with Compute in the Cloud and Data On-Prem
The second use case is bursting Spark workloads to the cloud with data on-premises in HDFS or an object store, as shown below. Alluxio connects the on-prem data stores and intelligently brings data close to Spark on-demand. This allows you to achieve high performance in a hybrid cloud environment without moving data manually.

A leading hedge fund with more than $50 billion under management utilized Alluxio for this use case. Their main requirements are performance (more machine learning models generated daily), security and agility. With Alluxio deployed, Spark workloads are in Google cloud and data remains on-premises in HDFS. By using Alluxio, they improved performance, achieved a 4x increase in model runs per day and a 95% saving in compute costs. Bringing Alluxio into their data platform requires no changes to the existing applications or storage infrastructure. Data is encrypted in Alluxio and there is no persistent storage in the cloud, ensuring the security requirements. Learn more about the use case in this case study.
Seamless Data Access Anywhere

In this use case, there are multiple compute frameworks and storage systems spanning different regions, both on-premises and in a public cloud. Such a mix brings unprecedented challenges for access to data. Alluxio unifies and synchronizes data across different infrastructure pieces in the data pipeline without changes to applications.
Alluxio's capabilities are fully utilized in this use case. Alluxio removes the complexity of the data management among various data silos and fully separates the compute frameworks and storage systems. As long as the applications interact with Alluxio, they do not have to worry about where the data is stored or how to move it because these are all handled by Alluxio.
A leading telecom company was looking to modernize the data platform over time and utilize new capabilities and find a pragmatic way without impacting end-user experience. They first used Alluxio to migrate to the cloud with data in the cloud and compute residing on-premises. Then, Alluxio provided a single view for multiple data centers and the ability to move data from one data center to another.
With Alluxio, the platform infrastructure allows them to analyze globally distributed data without the need for error-prone, time-consuming and manual data movement. Alluxio has provided a more agile approach to modernizing their data platform without impacting the end-user experience.
Performance Benchmarks and Cost Savings
Performance Benchmark
When comparing the total execution time for all 100 queries included in the TPC-DS benchmark, Alluxio shows a 57% increase in performance when compared to S3 with the standard Amazon EMR configuration. Refer to this white paper for more details.
Reduce Costs with Spot Instances
For a hybrid cloud environment with compute in the cloud and storage on-prem, using spot instances can significantly reduce costs. Alluxio can be deployed as on-demand standalone instances for storing cached data while Spark leverages spot instances. Caching using on-demand instances provides high data availability unimpacted from interruptions as compute instances may be reclaimed. Spot instances are much cheaper, and the number of on-demand instances required for Alluxio is only a fraction of the total cost.
To simulate a real-world scenario with spot instances, we “preempt” instances by manually terminating instances from the AWS console to simulate the real scenario as spot instances. We force the Spark driver to reschedule tasks on existing nodes by manually killing instances. We run two uninterrupted iterations as a baseline and then two interrupted Terasort jobs to validate this approach.
Uninterrupted Terasort(100 GB) Run Times
Spark on S3Spark on Alluxio4 minutes 12 seconds4 minutes 24 seconds
Interrupted Terasort(100 GB) Run Times
Spark on Alluxio (10 Alluxio Workers) Spark on Alluxio (20 Alluxio Workers) 8 minutes 56 seconds7 minutes 14 seconds
We then run DFSIO to measure the write throughput and found that 1 Alluxio cluster can serve 14 Spark clusters without a degradation in performance or latency. Also, leveraging Alluxio as a standalone cluster in the cloud retains similar performance.
With this baseline, we calculate the cloud cost savings with standalone Alluxio cluster for Spark on spot instance.
AWSGCP Topology to Support 1 User59%56%Topology to Support 50 Users74%75%
Thus we can see that the Alluxio cluster only accounts for a small fraction of the overall cost of the solution and this architecture can provide cost savings between 56-75% compared to not leveraging spot instances.
Get Started
If you’ve embraced Spark for business intelligence, data science, and machine learning applications, it’s time to start using Alluxio. With Alluxio, you can unify data silos, share data across computing frameworks and migrate data across environments seamlessly.
To get started with Spark + Alluxio, view this 5-min tutorial and documentation for more details. You can download the free Alluxio Community Edition or a trial of Alluxio Enterprise Edition here to discover the benefits of Spark + Alluxio for your own use cases. We work with the open source community to keep bringing further improvements and optimizations to the data ecosystem. Join the community slack channel today and engage with our users or developers.
Links
- Get Started: Getting Started with Spark Caching using Alluxio in 5 Minutes
- Performance Tuning Tips: Top 10 Tips for Making the Spark + Alluxio Stack Blazing Fast
- Documentation: Running Spark on Alluxio
.png)
Blog

Learn about the new features in Alluxio AI 3.8 designed to eliminate two of the most painful bottlenecks in modern AI pipelines. Introducing Alluxio S3 Write Cache, which dramatically reduces object store write latency and improves write-heavy workload performance, and Safetensors Model Loading Acceleration that delivers near-local NVMe throughput for model weight loading

For write-heavy AI and analytics workloads, cloud object storage can become the primary bottleneck. This post introduces how Alluxio S3 Write Cache decouples performance from backend limits, reducing write latency up to 8X - down to ~4–6 ms for concurrent and bursty PUT workloads.

Oracle Cloud Infrastructure has published a technical solution blog demonstrating how Alluxio on Oracle Cloud Infrastructure (OCI) delivers exceptional performance for AI and machine learning workloads, achieving sub-millisecond average latency, near-linear scalability, and over 90% GPU utilization across 350 accelerators.