Introduction
Spark has brought significant innovation to Big Data computing, but its results are even more extraordinary when paired with other open source projects in the ecosystem. Alluxio, formerly Tachyon, provides Spark with a reliable data sharing layer, enabling Spark to excel at performing application logic while Alluxio handles storage.
For example, global financial powerhouse Barclays made the impossible possible by using Alluxio with Spark in their architecture. Technology giant Baidu analyzes petabytes of data and realized 30x performance improvements with a new architecture centered around Alluxio and Spark; at that point, the gain in speed is an enabler for new workloads. With the Alluxio 1.0 release and an upcoming Spark 2.0 release, we’ve established a clean and simple way to integrate the pair.
This blog is a tutorial for those who are new to and interested in how to leverage Alluxio with Spark, and all of the examples will be reproducible on a local machine. In later blogs we will scale up to distributed clusters and dive deeper into using Alluxio and computation frameworks such as Spark.
Takeaways from this Blog
- How to set-up Alluxio and Spark on your local machine
- The benefits of leveraging Alluxio with Spark
- Data sharing between multiple jobs: Only one job needs to incur the slow read from cold data
- Resilience against job failures: Data is preserved in Alluxio across job failures or restarts
- Managed storage: Alluxio optimizes the utilization of allocated storage across applications
- Trade-offs between using in-memory Spark application storage and Alluxio storage
- How to connect Alluxio to external storage, such as S3
Getting Started
For the purposes of this tutorial, we will set up a working directory and assign it to an environment variable. This will make it easy to reference different project folders in the following code snippets.
mkdir alluxio-spark-getting-started cd alluxio-spark-getting-started export DEMO_HOME=$(pwd)
To get started with Alluxio and Spark, you will first need to download a distribution for the two systems. In this blog, we will use Alluxio 1.0.1 and Spark 1.6.1, but the steps are the same for other combinations of Alluxio 1.0+ and Spark 1.0+.
Setting up Alluxio
Download, extract, and start a precompiled release of Alluxio from the Alluxio website:
$ cd $DEMO_HOME $ wget https://downloads.alluxio.io/downloads/files/1.0.1/alluxio-1.0.1-bin.tar.gz $ tar xvfz alluxio-1.0.1-bin.tar.gz $ cd alluxio-1.0.1 $ bin/alluxio bootstrap-conf localhost $ bin/alluxio format $ bin/alluxio-start.sh local
Verify that the Alluxio system is running by visiting the web UI at localhost:19999/home.
Setting up Spark
Download a precompiled release of Spark from an Apache mirror (an example is provided below). Spark also needs an Alluxio client jar which let's Spark programs talk with Alluxio; this is the point of integration between the two systems.
After downloading, create a new Spark environment configuration by copying conf/spark-env.sh.template to conf/spark-env.sh. You can then make the Alluxio client jar available by adding it to the SPARK_CLASSPATH in the conf/spark-env.sh file; make sure to change the path to the path appropriate for your environment.
cd $DEMO_HOME wget http://apache.mirrors.pair.com/spark/spark-1.6.1/spark-1.6.1-bin-hadoop2.4.tgz tar xvfz spark-1.6.1-bin-hadoop2.4.tgz wget https://downloads.alluxio.io/downloads/files/1.0.1/alluxio-core-client-spark-1.0.1-jar-with-dependencies.jar cd spark-1.6.1-bin-hadoop2.4 cp conf/spark-env.sh.template conf/spark-env.sh echo 'export SPARK_CLASSPATH=/path/to/alluxio-core-client-spark-1.0.1-jar-with-dependencies.jar:$SPARK_CLASSPATH' >> conf/spark-env.sh
Running a Simple Example
As a first example, we will run Alluxio with Spark reading data from local storage to get familiar with the integration between the two systems.
Note that in this scenario the performance benefits of Alluxio are limited; the fast access to local storage and presence of the OS buffer cache greatly help the workload reading from disk. You may even see lower performance for smaller files due to the communication overhead taking up the bulk of the execution time.
For sample data, you can download a file which is filled with randomly generated words from an English dictionary.
cd $DEMO_HOME # compressed version wget https://s3.amazonaws.com/alluxio-sample/datasets/sample-1g.gz gunzip sample-1g.gz # uncompressed version wget https://s3.amazonaws.com/alluxio-sample/datasets/sample-1g
Start the spark-shell program by running the following command from the Spark project directory. In the interactive shell you can manipulate data from various sources, such as your local file system.
cd $DEMO_HOME/spark-1.6.1-bin-hadoop2.4 bin/spark-shell
Process the file in Spark and count how many lines are in the file, make sure to update the path to the path you downloaded the sample data to.
val file = sc.textFile("/path/to/sample-1g") file.count()
Alluxio can also be used as a source or sink for your data. You can save the file to Alluxio and similarly run the same operations on the data from Alluxio, as you would for your local file system.
val file = sc.textFile("/path/to/sample-1g") file.saveAsTextFile("alluxio://localhost:19998/sample-1g") val alluxioFile = sc.textFile("alluxio://localhost:19998/sample-1g") alluxioFile.count()
You should see the results of the two operations to be similar in performance, with Alluxio doing better for larger files.
Similar to how Alluxio stores the data in memory after being accessed, Spark will do so in Spark's application memory if you use the cache() API. However, there are some disadvantages compared to using Alluxio.
If you are using the 1 GB file, you will see issues with running out of space to cache the RDD in memory. This is expected because spark-shell runs by default with 1 GB memory and only allocates a configurable portion of that space to storage.
val file = sc.textFile("/path/to/sample-1g") file.cache() file.count() file.count()
You can reattempt the experiment after increasing the driver memory:
cd $DEMO_HOME/spark-1.6.1-bin-hadoop2.4 bin/spark-shell --driver-memory 4g
You should now see the performance of the second count to be much faster. However, the benefit of Spark cache is limited because the data is stored in JVM memory. In particular, as the data set gets larger, you will start to see performance degradation. In addition, the cache operation does not store the raw data, so you will often need more memory than the size of your file.
You can download a sample 2 GB file we provide here:
cd $DEMO_HOME # compressed version wget https://s3.amazonaws.com/alluxio-sample/datasets/sample-2g.gz gunzip sample-2g.gz # uncompressed version wget https://s3.amazonaws.com/alluxio-sample/datasets/sample-2g
As a simple example, we can allocate 4 GB to the spark-shell and attempt the commands with a 2 GB file. Due to storing Java objects in the JVM heap which are larger than the actual data, Spark will not be able to store the entire data set in memory. This will significantly decrease the performance of the job, taking longer than even just reading it from disk.
val file = sc.textFile("/path/to/sample-2g") file.cache() file.count() file.count()
A workaround would be store the serialized form of the objects which will not take as much space as the Java objects. The performance of the second count will be significantly faster. However, the data must be stored in the Spark process and will not be available after exiting the spark-shell or for other spark processes during the time it is open. In addition, it is hard to fully utilize Spark’s storage and execution fractions without manually tuning the configuration based on your workloads.
import org.apache.spark.storage.StorageLevel val file = sc.textFile("/path/to/sample-2g") file.persist(StorageLevel.MEMORY_ONLY_SER) file.count() file.count()
Alluxio can solve the mentioned issues with using Spark’s execution storage. To run the same example in Alluxio, we will first need to increase the amount of memory managed by Alluxio. Modify the line in Alluxio’s conf/alluxio-env.sh from 1GB to 3GB. This uses roughly equivalent memory compared to running spark-shell with 4 GB of memory (Alluxio 3 GB + spark-shell 1 GB). Then restart Alluxio for the changes to take effect.
cd $DEMO_HOME/alluxio-1.0.1 vi conf/alluxio-env.sh # Modify the memory size line to 3GB in the file, then save and exit export ALLUXIO_WORKER_MEMORY_SIZE=${ALLUXIO_WORKER_MEMORY_SIZE:-3GB} bin/alluxio-start.sh local
Afterward, we can add the same file to the Alluxio system. You can do this easily through the Alluxio shell, or the spark-shell like we did previously.
cd $DEMO_HOME/alluxio-1.0.1 bin/alluxio fs copyFromLocal ../sample-2g /sample-2g cd $DEMO_HOME/spark-1.6.1-bin-hadoop2.4 bin/spark-shell
We can attempt the same example as before, but with the larger file. You should also have no problems reading the smaller file from Alluxio.
val alluxioFile2g = sc.textFile("alluxio://localhost:19998/sample-2g") alluxioFile2g.count() val alluxioFile1g = sc.textFile("alluxio://localhost:19998/sample-1g") alluxioFile1g.count()
Here are some results using 1 GB spark-shell and 3 GB Alluxio or in the cases of Spark only, 4 GB spark-shell (lower is better).
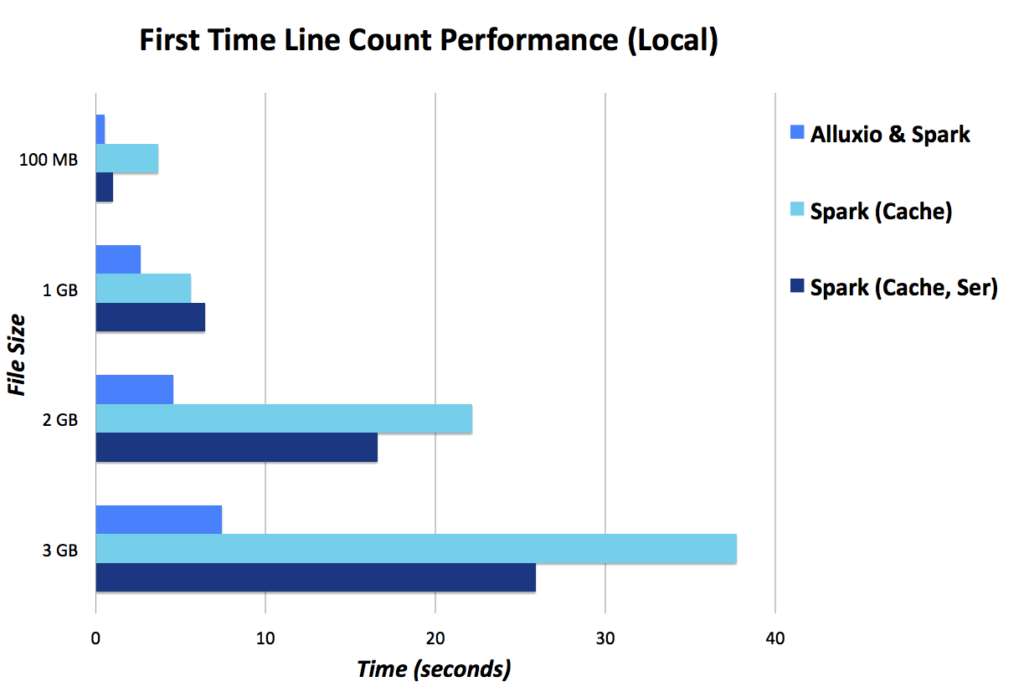
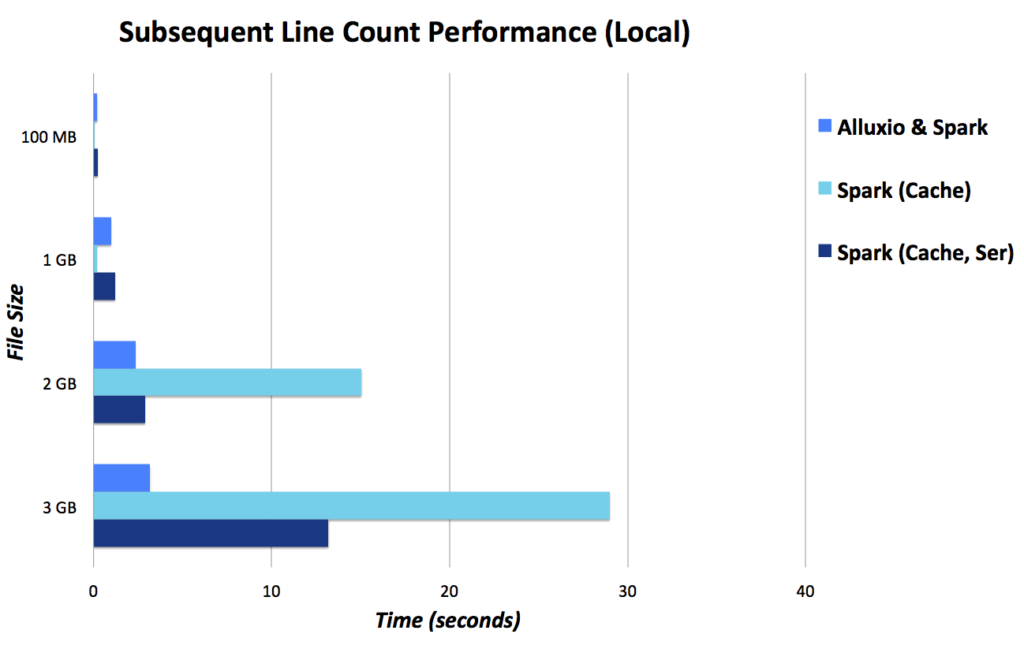
Remote Data Access
Now that we have breached the surface of integrating Alluxio and Spark, we can try out an examples which will be more reflective of a real production environment. In this example we will use S3 as our data source, but it can be replaced with another storage system.
Often, data will not be available on your local machine and is available in a shared data store. In this situation, Alluxio immediately brings the benefit of being able to connect to the remote storage transparently. This means instead of changing the code to use another client or update the file path, you can continue using the Alluxio path as if the file was in the same namespace.
In addition, many people may be querying the same dataset, for example the members of a data science team. Using Alluxio amortizes the expensive call to fetch data from S3 and saves memory by keeping the data in the shared Alluxio space once. This way, as long as one person has accessed the data, all subsequent calls will be from Alluxio memory.
Let's take a look at how we can access a dataset in S3.
First, update Alluxio with the intended data store. A public, read-only S3 bucket is available with sample datasets under the S3 bucket s3n://alluxio-sample/datasets
Then, specify your S3 credentials to Alluxio by setting the environment variables in alluxio-env.sh.
You do not need any permissions for the bucket, but you will need to be an AWS user to access S3.Store your keys in the environment variables AWS_ACCESS_KEY and AWS_SECRET_KEY, then update alluxio-env.sh.
cd $DEMO_HOME/alluxio-1.0.1 export AWS_ACCESS_KEY=YOUR_ACCESS_KEY export AWS_SECRET_KEY=YOUR_SECRET_KEY vi conf/alluxio-env.sh # Modify the ALLUXIO_JAVA_OPTS to add the two parameters export ALLUXIO_JAVA_OPTS+=" -Dlog4j.configuration=file:${CONF_DIR}/log4j.properties ... -Dfs.s3n.awsAccessKeyId=$AWS_ACCESS_KEY -Dfs.s3n.awsSecretAccessKey=$AWS_SECRET_KEY "
Now restart the Alluxio system to provide the Alluxio servers with the necessary credentials. Afterward, you can directly connect Alluxio with the S3 bucket by using the mount operation. This will make any accesses to the Alluxio path /s3 go directly to the S3 bucket.
cd $DEMO_HOME/alluxio-1.0.1 bin/alluxio-start local bin/alluxio fs mount /s3 s3n://alluxio-sample/datasets
You will also need to add S3 credentials to your Spark environment. Do so by adding the following lines in conf/spark-env.sh:
cd $DEMO_HOME/spark-1.6.1-bin-hadoop2.4 vi conf/spark-env.sh export SPARK_DAEMON_JAVA_OPTS+=" -Dfs.s3n.awsAccessKeyId=$AWS_ACCESS_KEY -Dfs.s3n.awsSecretAccessKey=$AWS_SECRET_KEY "
If you were simply using Spark, you can access the data in the following manner in spark-shell. You will notice the speed is much slower than local disk, due to the remote data access. To avoid this on subsequent calls, you can cache the data, but your Spark memory needs to be as large as the dataset (or even larger if not using serialized cache), and the data needs to be cached in each Spark context which will not be shared among different applications or users. Note that the following example will take a few minutes, depending on your network bandwidth. You can also use the sample 100 MB file found at s3n://alluxio-sample/datasets/sample-100m.
val file = sc.textFile("s3n://alluxio-sample/datasets/sample-1g") file.count() val cachedFile = sc.textFile("s3n://alluxio-sample/datasets/sample-1g") cachedFile.cache() cachedFile.count()
Using Alluxio, you can access the data under the S3 path. You may notice the performance is similar, this is because the first read is the same in both cases, the data is remote in S3. However, you will notice for subsequent reads, the performance is orders of magnitude better with Alluxio because the data is stored in local memory. You can imagine for non-trivial workloads such as data processing pipelines or iterative machine learning, the number of times the data is accessed will be much more than 1.
To avoid the first time access cost, you can prefetch the data using the load command from the Alluxio shell.
cd $DEMO_HOME/alluxio-1.0.1 bin/alluxio fs load /s3/sample-1g
If you don't prefetch the data, one caveat for loading data from S3 to Alluxio on-the-fly is to set the partition size to one to ensure the file will be loaded into Alluxio. However, when reading the data, you should partition the file as you see fit.
val file = sc.textFile("alluxio://localhost:19998/s3/sample-1g", 1) file.count() val file = sc.textFile("alluxio://localhost:19998/s3/sample-1g", 8) file.count()
Here are performance numbers with a 10 MB/s connection to S3. The Alluxio and Spark set up allocates 3 GB to Alluxio and 1 GB to spark-shell, whereas the Spark only set ups allocate 4 GB to spark-shell (lower is better).
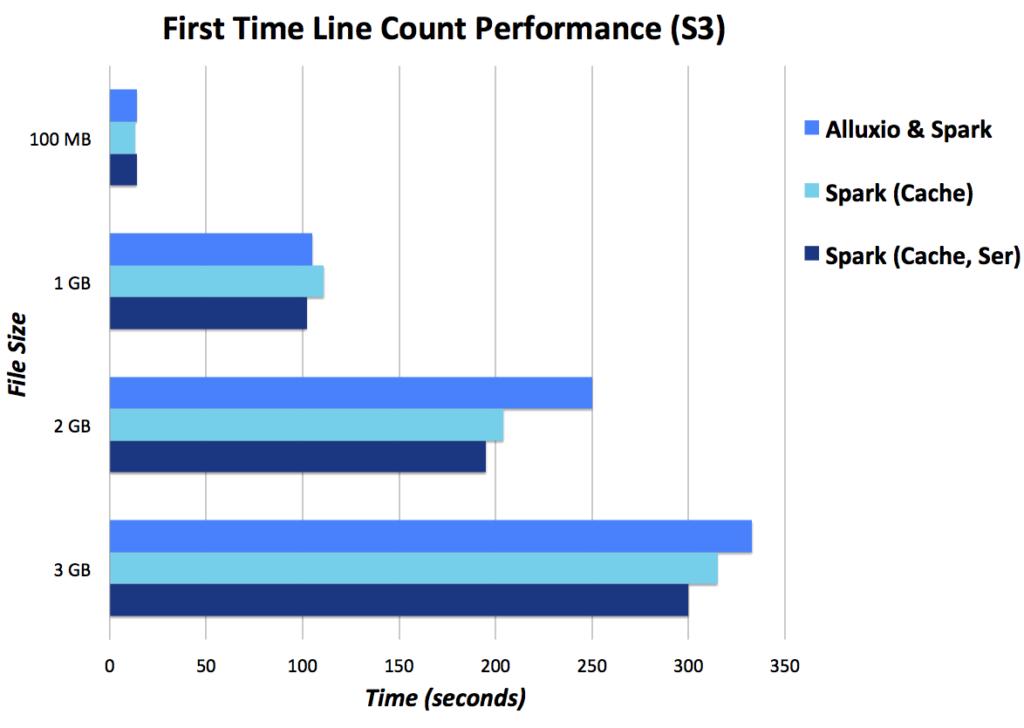
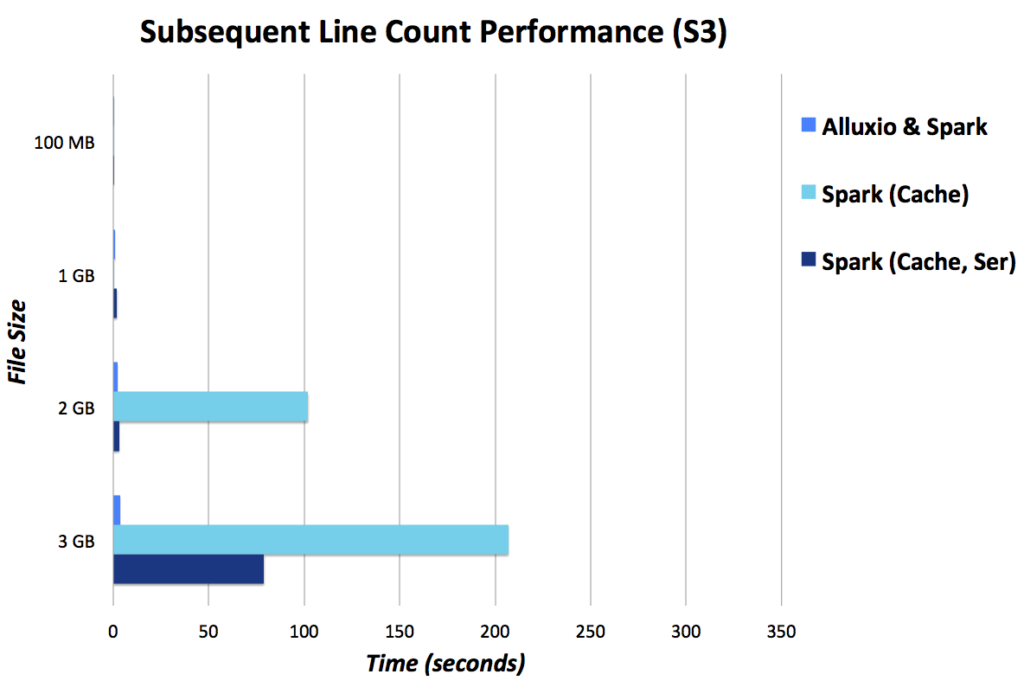
Conclusion
This is an introduction to using Alluxio with Spark. Subsequent blogs will go more in depth into use cases and architectures involving Alluxio and computation frameworks such as Spark.
We have an on-demand tech talk on how to accelerate Spark workloads on S3 that I recommend.
Please let us know whether this blog was helpful and what you'd like to see next by contacting us at blogs@alluxio.com.
.png)
Blog

Suresh Kumar Veerapathiran and Anudeep Kumar, engineering leaders at Uptycs, recently shared their experience of evolving their data platform and analytics architecture to power analytics through a generative AI interface. In their post on Medium titled Cache Me If You Can: Building a Lightning-Fast Analytics Cache at Terabyte Scale, Veerapathiran and Kumar provide detailed insights into the challenges they faced (and how they solved them) scaling their analytics solution that collects and reports on terabytes of telemetry data per day as part of Uptycs Cloud-Native Application Protection Platform (CNAPP) solutions.
.png)

With the new year comes new features in Alluxio Enterprise AI! Just weeks into 2025 and we are already bringing you exciting new features to better manage, scale, and secure your AI data with Alluxio. From advanced cache management and improved write performance to our Python SDK and S3 API enhancements, our latest release of Alluxio Enterprise AI delivers more power and performance to your AI workloads. Without further ado, let’s dig into the details.