

Co-hosted by Alluxio and Uber on May 23, 2024, AI/ML Infra Meetup was the community event for developers focused on building AI, ML and data infrastructure at scale. We were thrilled by the overwhelming interest and enthusiasm in our meetup!
This event brought together over 100 AI/ML infrastructure engineers and enthusiasts to discuss the latest advancements in ML pipeline, AI/ML infrastructure, LLM, RAG, GPU, PyTorch, HuggingFace and more. Experts from Uber, NVIDIA, Alluxio, and University of Chicago joined together at Uber’s Sunnyvale office to share insights and real-world examples about optimizing data pipelines, accelerating model training and serving, designing scalable architectures, and other cutting-edge topics.
ML Explainability in Michelangelo, Uber’s ML Platform
Eric (Qiusheng) Wang, Senior Software Engineer at Uber
The evening commenced with Eric (Qiusheng) Wang, Senior Staff Software Engineer at Uber, who has been on Uber’s Michelangelo team since 2020, focusing on maintaining high ML quality across all models and pipelines. In his talk, he shared the methodologies Uber employs to explain deep learning models and how these techniques have been integrated in the Uber AI Michelangelo ecosystem to support offline explanations.
Machine learning (ML) explainability involves understanding how models operate, make decisions, and interpret various scenarios. Uber runs over one thousand machine learning pipelines daily, training numerous models on these pipelines. Thus, it is critical for teams at Uber to understand these models thoroughly and ensure they function correctly and are free from biases. Uber is currently exploring several explanation methods, including KernelShap and Integrated Gradients.

Diagram 1: Explanation Methods (source)
To conclude his session, Eric revealed that Uber is developing an explainability framework called the XAI Framework. This framework is designed to explain machine learning models at scale and provide a distributed solution. It aims to address Uber’s challenges with Integrated Gradients in their model serving pipeline, with a focus on data processing, explainer modules, model wrappers, and importance aggregation.

Diagram 2: XAI Framework (source)
Q: Have you compared the performance of [XAI Framework] with open source counterparts, like PyTorch Captum, which also uses integrated gradients for feature attribution and layer attribution?
A: We are using the open source solution from Captum Alibi, their Python library, and we made some modifications on top of that. If there are any library upgrades, we will benefit from that while also being able to make small modifications to cater to Uber’s numerous use cases. Underneath the hood, it’s an open source library.
Improve Speed and GPU Utilization for Model Training and Serving
Lu Qiu, Data & AI Platform Tech Lead at Alluxio and PMC maintainer of open source Alluxio
Siyuan Sheng, Senior Software Engineer at Alluxio
Inefficient data access leads to significant bottlenecks in end-to-end machine learning pipelines, particularly as training data volumes increase and large model files become more prevalent for serving. Lu Qiu, Data & AI Platform Tech Lead at Alluxio and PMC maintainer of open source Alluxio, offered an in-depth analysis of the causes for bottlenecks during data loading. These bottlenecks include the separation of compute and storage, large data volumes, congested networks, slow data transfer rates, and storage request rate limits or outages.
She then demonstrated how Alluxio, a high-performance data access layer, in conjunction with Ray for data preprocessing, can improve the speed of data loading and preprocessing. This optimization subsequently improves and optimizes GPU utilization for model training and serving in AI workloads. Alluxio serves as a distributed cache between AI frameworks, such as Ray and PyTorch, and remote storage systems, like S3 and HDFS.

Diagram 3: Speed up data loading & preprocessing for AI training (source)
Siyuan, Senior Software Engineer at Alluxio, then delved into the technical components of Alluxio’s architecture that enable high scalability, performance, stability, and reliability. Alluxio’s distributed architecture supports the caching of over 10 billion objects, thanks to its horizontal scalability without single node dependency. It also delivers high throughput, reaching approximately hundreds of gigabytes per second per Alluxio cluster. As our expert on cloud-native and AI frameworks, lastly he shared our latest integration of Ray and Alluxio with fsspec.

Diagram 4: Ray + Alluxio Fsspec: Easy Usage (source)
Q: Does Alluxio support data filtering based on metadata?
A: Alluxio offers cache filters that allows users to selectively cache “hot data” based on their needs. This is particularly useful in many AI and ML workloads because only a small percentage, around 20%, of data is actually used for 80% of training workloads.
Q: How does Alluxio compare to Ray’s object store for caching data?
A: Ray’s object store only caches data for individual tasks within a single node, while Alluxio caches data globally across different tasks and machines. In that sense, for many users Alluxio potentially leads to better caching efficiency.
Q: How does Alluxio manage data parallelization across multiple GPU servers?
A: Alluxio fetches data via Python API and POSIX APIs; for those frameworks, data access already issues a parallel request. Alluxio also uses a Rust library on the client side to handle and scale out parallel data requests for multi-threading in the Python process.
Reducing Prefill for LLM Serving in RAG
Junchen Jiang, Assistant Professor of Computer Science at University of Chicago
Large language models (LLMs) are increasingly prevalent, yet the prefill phase in LLM inference remains resource-intensive, especially for extensive LLM inputs. Junchen Jiang, Assistant Professor of Computer Science at University of Chicago, shares his preliminary efforts towards significantly reducing prefill delay for LLM inputs that naturally reuse text checks, such as in retrieval-augmented generation (RAG).
Given that prefill delays will inevitably increase with longer contexts and larger models, the proposed system employs knowledge sharing. In this approach, the pre-processed information, known as KV cache, learned from one LLM can be shared with others. The advantages of adopting knowledge sharing include up to 50x faster time-to-first-token, increased throughput by processing 5x more requests per second, and cost reductions of up to 4x when storing the KV cache on SSDs.

Diagram 5: Speed comparison with and without KV cache (source)
A significant challenge with large KV caches is the extensive loading time due to network transfer, contributing to overall delay. Compressing the KV cache leads to much faster loading times, thereby reducing the overall delay. Introducing CacheGen, a system for KV cache compression and streaming for fast language model serving, which encodes the KV cache and stores it as a compact binary representation. This compressed cache can be quickly loaded into the GPU and decoded for immediate use.

Diagram 6: CacheGen: Compressing KV cache for fast prefill (source)
Q: How does your research related to vector databases?
A: Vector databases address a different problem with indexing knowledge for efficient retrieval. KV cache focuses on optimizing how models read and process retrieved documents after the indexing system identifies them. Though they serve different purposes, they both play crucial roles in different parts of the data storage and retrieval process.
Q: Are there any resilience issues when sharing the cache between different models?
A: By default, to share KV cache, two models must have identical weights because the first model producing the KV cache must be the same model using the KV cache. However, it’s a grey area. Interestingly, if two models are fine-tuned from the same pre-trained model, there’s a high chance for those two models to share the KV cache, even if those two models are not identical. It is a very active research area.
My Perspective on Deep Learning Framework
Dr. Triston (Xiande) Cao, Senior Deep Learning Software Engineering Manager at NVIDIA
Deep learning frameworks are essential tools that provide a structured environment for building and training complex AI models. They manage core functionalities such as neural network creation, backpropagation for error correction, and efficient data processing. To conclude the event, Dr. Triston Cao, Senior Deep Learning Software Engineering Manager at NVIDIA, offered his insights on the evolution of deep learning frameworks, tracing their progression from Caffe to MXNet to PyTorch and beyond.
In the early days, deep learning frameworks like Tensorflow, PyTorch, and MXNet focused on optimization techniques like tensor core utilization, reduced precision floating-point computation, and kernel fusion to significantly enhance training and inference speeds. Optimizations for data layouts, such as NHWC (Number of samples, Height, Width, Channels) and NCHW (Number of samples, Channels, Height, Width), were developed to streamline data loading and improve training efficiency.

Diagram 7: Open-source Frameworks (source)
Fast forward to today, compiler-based frameworks like Lightning Thunder and JAX are gaining traction, offering efficient on-the-fly code optimization for a variety of hardware platforms, including edge devices and mobile. The future of deep learning frameworks is centered on providing a seamless experience for researchers and developers, enabling them to concentrate on model development and deployment without being hindered by the complexities of the framework.

Diagram 8: Compiler Based Framework (source)
Q: On the inference side, how much trend are you seeing towards clusters for inference, for things like Ring Attention where you’re trying to build massive context windows and one GPU, or one DGX, might not be enough?
A: Honestly I am not an inference expert, but I think caching seems to be a big focus for inference to avoid re-compute, especially for large transformer models. Clustering for inference may depend on specific latency requirements designated by the user.
Q: What’s your perspective on Onyx? Do you see a lot of usage at NVIDIA and do you think it serves a purpose for the inference stack?
A: Onyx became an interface that inference frameworks can use. In general, I think it’s good. Onyx is something that both large companies focused research and open source communities can talk about. It terms of how far it will go, it really depends on the open source community and its contributors to continue growing and contributing to the project.
.png)
Blog

Oracle Cloud Infrastructure has published a technical solution blog demonstrating how Alluxio on Oracle Cloud Infrastructure (OCI) delivers exceptional performance for AI and machine learning workloads, achieving sub-millisecond average latency, near-linear scalability, and over 90% GPU utilization across 350 accelerators.
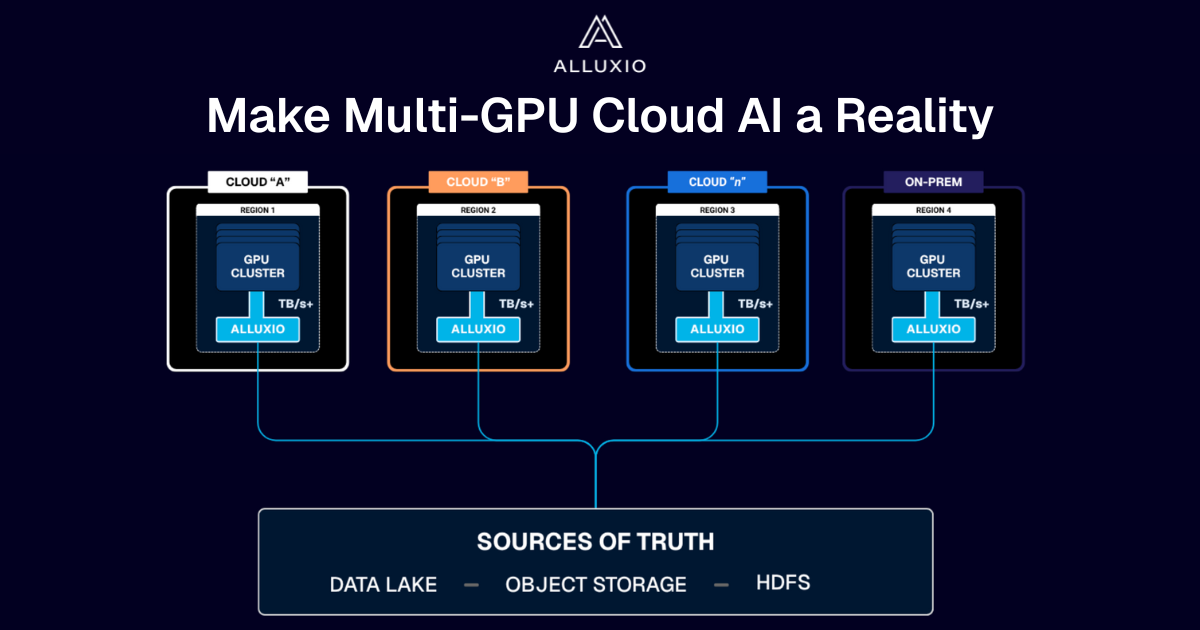
If you’re building large-scale AI, you’re already multi-cloud by choice (to avoid lock-in) or by necessity (to access scarce GPU capacity). Teams frequently chase capacity bursts, “we need 1,000 GPUs for eight weeks,” across whichever regions or providers can deliver. What slows you down isn’t GPUs, it’s data. Simply accessing the data needed to train, deploy, and serve AI models at the speed and scale required – wherever AI workloads and GPUs are deployed – is in fact not simple at all. In this article, learn how Alluxio brings Simplicity, Speed, and Scale to Multi-GPU Cloud deployments.
