TL;DR: Nilesh Agarwal, Co-Founder & CTO at Inferless shares how they have solved critical I/O bottlenecks in LLM inference infrastructure by implementing Alluxio, achieving 12x faster model loading and 10x throughput, reducing cold start times from minutes to seconds, and significantly improving customer experience.
1. I/O Challenges Scaling LLM Inference Infrastructure
At Inferless, we provide companies with a serverless platform to effortlessly deploy custom Large Language Models (LLMs). Our LLM inference infrastructure is at the core of enabling seamless, high-performance model deployment at scale.
LLM model files, including model weights, are typically quite large (often many gigabytes) and must be loaded quickly into GPU memory across all inference servers supporting the LLM workloads. A core challenge is the "cold start" problem – the delay when loading a model into GPU memory for the first time or after a period of inactivity.
At Inferless, we help hundreds of customers deploy thousands of models. In a typical setting, an inference request involves being routed through a load balancer and then directed to a node. If a replica of a container image isn't immediately available, the system initiates a three-step process: starting the container image, pulling the model weights, and finally performing the inference. The step of pulling model weights can introduce bottlenecks that hinder the performance and scalability of our platform. For example, if thousands of inference nodes each pull a 20 to 100 GB model from a cloud object store or a centralized NFS, network bandwidth and storage I/O quickly become bottlenecks.
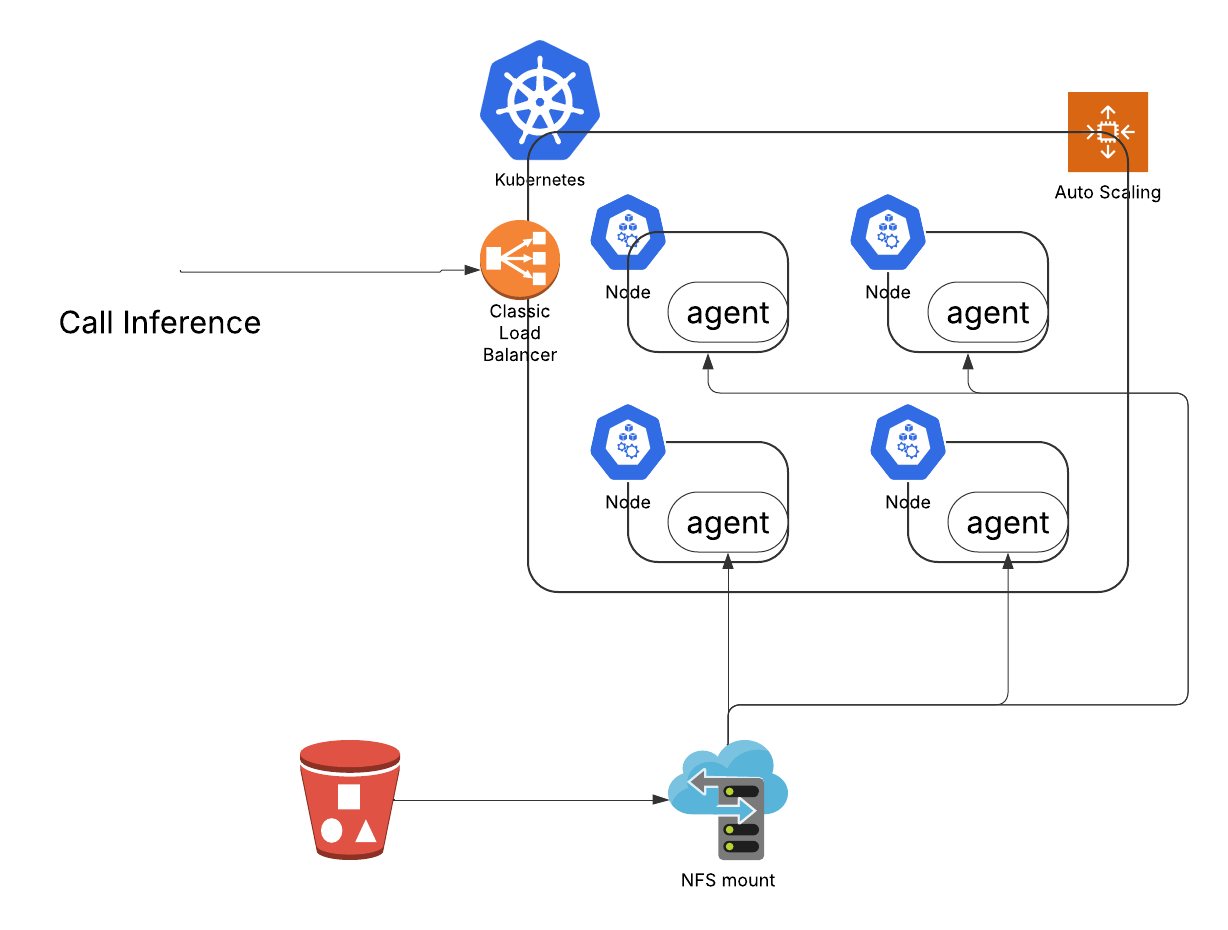
More specifically, we have encountered the following limitations while scaling our LLM inference infrastructure:
- Cloud object storage cannot meet the throughput and latency demands. Models are typically stored in cloud object storage (S3, GCS, Azure Blob). Pulling large models (ranging from 20GB to over 100GB) directly from these storage is very slow, often only 200-500 Mbps.
- NFS limitations in performance and costs. While NFS seems straightforward, based on our experience, a centralized NFS solution quickly becomes expensive and a performance bottleneck when many nodes simultaneously attempt to pull model weights. It struggles with concurrent access at scale.
- No native LRU caching of model weights. Without an efficient, intelligent caching mechanism close to the compute, repeated pulls of the same model weights from cloud storage degrade performance and unnecessarily increase data transfer costs.
- Need POSIX-compliant interface for LLM frameworks. Modern LLM inference frameworks like PyTorch and Hugging Face often expect standard filesystem operations (mmap for formats like Safetensors). Achieving this efficiently with direct object storage access under high-throughput demands can be complex and sub-optimal.
2. Cut Model Loading Time by 12x Using Alluxio
To address our challenges, we have explored various solutions, where Alluxio stands out both architecturally and in performance.
Alluxio serves as a distributed caching layer between cloud storage and LLM applications. Alluxio’s distributed cache makes use of the fast but often underutilized NVMe drives available on cloud GPU nodes, which significantly reduces model load times. Additionally, Alluxio’s integration with S3 extracts data more efficiently than typical methods using libraries like boto3. Alluxio’s S3 integration enables parallel loading, achieving high throughput for model loading.
2.1 Three-Tier Architecture with Alluxio
With Alluxio, we have achieved a robust three-tier storage architecture that underpins LLM inference optimization. This approach is now considered a best practice for LLM serving in cloud environments.
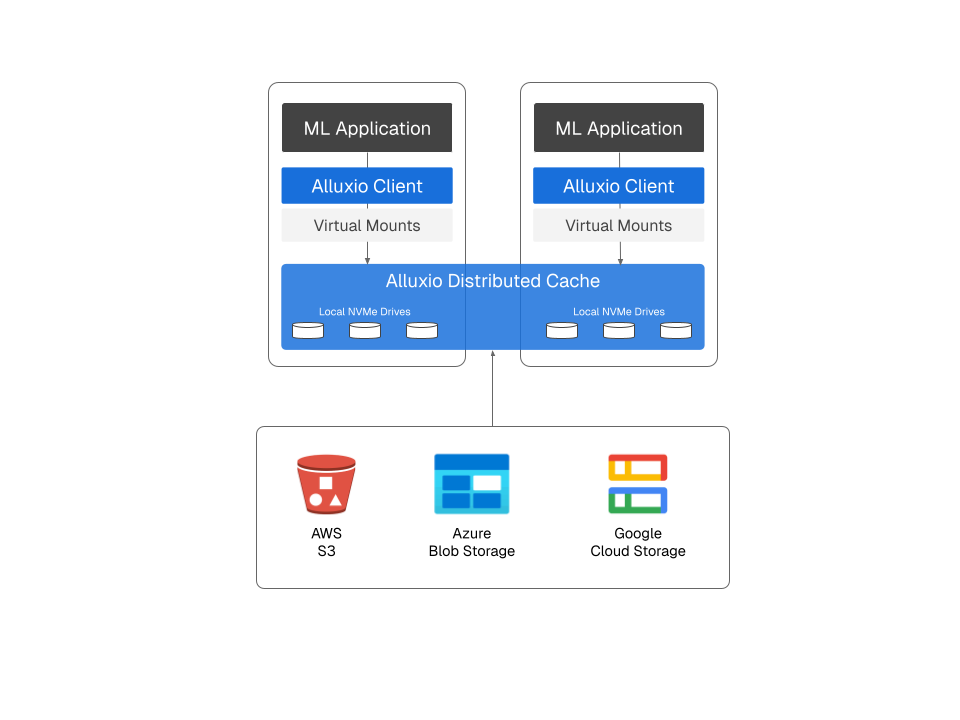
Hot Tier (Alluxio): Local NVMe with POSIX Interface
Each compute node has a fast NVMe SSD (or NVMe-based instance storage) mounted as a POSIX filesystem.
Alluxio intelligently utilizes the fast, often underutilized, local NVMe SSDs present on each GPU server. Through Alluxio FUSE, this tier is exposed as a POSIX-compliant virtual mount to the inference containers. This provides “hot” data access with extremely high throughput (on the order of ~2.5 GB/s or more per node) and low latency, ensuring model files can be read at near in-memory speeds.
Warm Tier (Alluxio): Intra-Cluster File Sharing
On the cluster level, nodes share data with each other. Each machine exposes a service (or participates in a distributed filesystem) so that peers can retrieve model files from one another over the high-speed network.
Alluxio workers deployed on different nodes within the same Kubernetes cluster or availability zone can share data cached from the cold tier. If a model isn't found in a node's local Alluxio hot tier (NVMe), Alluxio first checks if a peer node within the cluster has already cached it. This “warm” layer means if one node has a model cached on its NVMe, other nodes can fetch it at ~2 GB/s over the LAN instead of all hitting the cloud storage.
Cold Tier: Cloud Object Storage (S3, Azure Blob, GCS)
This is the durable, scalable source of truth where all model weights are persistently stored, serving as the “cold” storage for all model and data artifacts. It provides virtually infinite capacity and durability, but with higher latency (hundreds of milliseconds) and lower per-connection throughput. The cold tier is the source of truth from which data is pulled into the faster tiers on demand, and it’s used as a fallback for cache misses or to populate the upper tiers.
Alluxio provides optimized clients (e.g., a custom client for S3) that enable parallel loading from cloud object storage, minimizing direct cold reads, which in turn reduces latency, data egress costs, and API request fees.
2.2 Performance Benchmark
In terms of throughput, we achieved up to ~2 Gbps for model loading from cloud storage using Alluxio, which is 10x better than the previous ~200 Mbps.
For model loading times, at the same baseline throughput of 1 GB/s, we reduced loading times by 6 to 12x compared with Amazon FSx Lustre. A 5GB model now loads in just 2 seconds (hot cache) or 9 seconds (cold cache), down from 24 seconds previously. Similarly, a 24GB model loads in 8 seconds (hot cache) or 35 seconds (cold cache), compared to 50 seconds with Amazon FSx Lustre.
3. The Impact: Transforming LLM Serving Performance
The implementation of Alluxio has fundamentally transformed our LLM serving capabilities. What once required minutes of waiting for model initialization now happens in seconds, enabling true on-demand scaling and dramatically improving our customers' experience.
- 10x Throughput and 6-12x Faster Model Loading. We have achieved much better performance in solving the cold start problem. This fundamental improvement in data access speed is key to our product's success and responsiveness
- Enhanced Customer Experience & SLAs. This 12x performance gain in data loading can translate into a 2x improvement in the end-to-end user experience on our Inferless platform, allowing us to meet stringent P95 SLA requirements.
- Cost Efficiency for Customers. By eliminating lengthy cold starts and enabling rapid, on-demand scaling, we help our customers avoid the need to over-provision expensive GPU resources, leading to significant cost savings.
- Simplified Operations. Alluxio provides a unified, high-speed data access layer, replacing a complex, self-managed multi-storage solution for caching, thereby simplifying our operational overhead.
4. Summary
Deploying large-scale LLM inference in the cloud demands high throughput that can keep hundreds of GPUs fed with data without undue delay from cold starts. As Inferless scales to thousands of AI models across hundreds of GPU instances, the latency of loading models during the “cold start” was a persistent challenge, even when evaluating parallel file system solutions such as Amazon FSx for Lustre. Alluxio has been a game-changer, providing 6 to 12x faster model loading times and the critical multi-cloud agility we need for our serverless GPU compute service. By addressing the fundamental I/O challenges with Alluxio, the throughput of loading LLM weights can achieve a 10x improvement, approaching hardware limits (gigabytes per second throughput). With Alluxio, we can optimize our infrastructure to empower companies to deploy custom LLMs with unprecedented speed and efficiency.
.png)
Blog

Alluxio's strong Q2 featured Enterprise AI 3.7 launch with sub-millisecond latency (45× faster than S3 Standard), 50%+ customer growth including Salesforce and Geely, and MLPerf Storage v2.0 results showing 99%+ GPU utilization, positioning the company as a leader in maximizing AI infrastructure ROI.


In this blog, Greg Lindstrom, Vice President of ML Trading at Blackout Power Trading, an electricity trading firm in North American power markets, shares how they leverage Alluxio to power their offline feature store. This approach delivers multi-join query performance in the double-digit millisecond range, while maintaining the cost and durability benefits of Amazon S3 for persistent storage. As a result, they achieved a 22 to 37x reduction in large-join query latency for training and a 37 to 83x reduction in large-join query latency for inference.